カーネルモジュール作成によるlinuxカーネル開発入門 - 第四回 リスト
はじめに
本記事は第三回の続きです。前回までの記事を既に見ていることが前提です。
今回はカーネル内の代表的なデータ構造であるリストについて学びます。その過程で、カーネル内においてメモリを動的に割り当てる方法についても学びます。
リストの構造
リストの構造体の定義は次の通り、双方向リストです。
struct list_head { struct list_head *next, *prev; };
見てわかるように、リストそのものには数値、文字列などの実要素を埋め込むようなフィールドは用意されていません。かわりに、リストそのものを構造体に埋め込むという使い方をします。やや使い方に癖がありますが、慣れてくると非常に便利です1。
では、例としてmylistという名前がついた空のリストがあるとします。リストは次のように初期化します。
static LIST_HEAD(mylist);
行頭のstaticは、リストをモジュール内でのみ使う場合に指定します。そうでない場合はつけなくて構いません。他のモジュールに変数を公開する方法についてはあとの章で述べる予定です。
mylistは次の図のような双方向の構造をしています。

このmylistはnという名前の数値のフィールドをひとつ持つとしましょう。この場合、次のように当該リストのエントリ用の構造体を作成します。
struct mylist_entry { struct list_head list; int n; };
データ構造に直接 pref, next などのリンク構造を示すフィールドを用意せずにリスト専用のデータ構造を埋め込むことによって、このリストを使うあらゆるデータ構造に対して、リストを操作するAPIを1つに統一できるという利点があります。
このリストが1という数値を持つエントリをひとつだけ持つ時、リストは次のような構造になります。

同、1,10,100という3つの数値を持つエントリの場合、次のようになります。

いずれのリストも、リストそのものを示すmylistは意味のある値を全く持たないことに注意してください。
最も単純なリストの使用方法
リストの使用方法を学ぶために、次のようなモジュールを作ります。
- 要素に数値を持つリストを作成する
- モジュールロード時に空のリストmylistに次のような操作をする
- 先頭に1を追加
- 先頭に2を追加
- 先頭に3を追加
- 先頭から2つの要素を削除
- 末尾に4を追加
- 先頭から2つの要素を削除して空にする
- 操作するたびにカーネルログに操作内容と操作後のリストの内容を表示する
ソースは次の通りです。
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/list.h>
MODULE_LICENSE("GPL v2");
MODULE_AUTHOR("Satoru Takeuchi <satoru.takeuchi@gmail.com>");
MODULE_DESCRIPTION("an example of list data structure");
static LIST_HEAD(mylist);
struct mylist_entry {
struct list_head list;
int n;
};
static void mylist_add(int n) {
struct mylist_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add(&e->list, &mylist);
printk(KERN_ALERT "mylist: %d is added to the head\n", n);
}
static void mylist_add_tail(int n) {
struct mylist_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add_tail(&e->list, &mylist);
printk(KERN_ALERT "mylist: %d is added to the head\n", n);
}
static void mylist_del_head(void) {
struct mylist_entry *e = list_first_entry(&mylist, struct mylist_entry, list);
int n = e->n;
list_del(&e->list);
kfree(e);
printk(KERN_ALERT "mylist: %d is deleted from the head\n", n);
}
static void mylist_show(void) {
struct mylist_entry *e;
printk(KERN_ALERT "mylist: show contents\n");
list_for_each_entry(e, &mylist, list) {
printk(KERN_ALERT "\t%d\n", e->n);
}
}
static int mymodule_init(void) {
mylist_show();
mylist_add(1);
mylist_show();
mylist_add(2);
mylist_show();
mylist_add(3);
mylist_show();
mylist_del_head();
mylist_show();
mylist_del_head();
mylist_show();
mylist_add_tail(4);
mylist_show();
mylist_del_head();
mylist_show();
mylist_del_head();
mylist_show();
return 0;
}
static void mymodule_exit(void) {
/* Do nothing */
}
module_init(mymodule_init);
module_exit(mymodule_exit);
重要なポイントは次の通りです。
- kmalloc()によって動的にメモリを獲得する(ユーザプログラムにおけるmalloc()に相当)。第二引数はメモリ獲得時の諸条件を指定するフラグ。通常GFP_KERNEL。現段階ではあまり気にしなくて良い(後の章で説明予定)
- list_add()によって新規エントリをリスト先頭に追加
- list_add_tail()によって新規エントリをリスト末尾に追加
- list_del()によってエントリをリストから追加(本関数にリストそのものは指定しなくてよいことに注意)
- list_for_each()によってリストの全要素にアクセス
- list_for_each_safe()はlist_for_each()とほぼ同じだが、参照中のエントリを削除しても次の要素を安全に辿れる
- list_first_entry()によってlistの最初の要素を得る
このモジュールをロードすると次のようなログが出力されます。
# dmesg ... [ 6010.587046] mylist: show contents [ 6010.588791] mylist: 1 is added to the head [ 6010.590596] mylist: show contents [ 6010.592209] 1 [ 6010.593883] mylist: 2 is added to the head [ 6010.595695] mylist: show contents [ 6010.597318] 2 [ 6010.598625] 1 [ 6010.600152] mylist: 3 is added to the head [ 6010.601875] mylist: show contents [ 6010.603381] 3 [ 6010.604584] 2 [ 6010.605776] 1 [ 6010.606951] mylist: 3 is deleted from the head [ 6010.608662] mylist: show contents [ 6010.610167] 2 [ 6010.611347] 1 [ 6010.612476] mylist: 2 is deleted from the head [ 6010.614083] mylist: show contents [ 6010.615488] 1 [ 6010.617240] mylist: 4 is added to the head [ 6010.618830] mylist: show contents [ 6010.620254] 1 [ 6010.621378] 4 [ 6010.622476] mylist: 1 is deleted from the head [ 6010.624078] mylist: show contents [ 6010.625443] 4 [ 6010.626501] mylist: 4 is deleted from the head [ 6010.628052] mylist: show contents #
リストを使ったスタックの実装
前節のように、モジュールロード時に処理が全て終わってしまうのはあまり面白くないので、以前学んだdebugfsと今回学んだリストを用いて、ユーザから操作できるスタックをカーネル内に実装してみます。仕様は次の通りです。
- /sys/kernel/debugfs/mystack/以下にインターフェイスを持つ(以下このファイルを単にmystack/と表記)
- mystack/ 以下のファイルによって数値を格納するスタックを操作する。初期状態のスタックは空
- mystack/show からスタックの全要素を示す文字列を読み出す。要素間は空白で区切り、文字列の末尾には改行を置く
- mystack/push に数値を示す文字列を書き込むと、スタックの先頭に対応する要素を追加する。一度に追加できる要素の数は1つ
- mystack/pop を先頭から読み出すと、スタックの先頭要素を示す文字列を読み出した上で当該要素を削除する。先頭以外から読み出すと、何もせずに終了
コードは次の通りです。
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/debugfs.h>
MODULE_LICENSE("GPL v2");
MODULE_AUTHOR("Satoru Takeuchi");
MODULE_DESCRIPTION("a stack example implemented with list");
struct mystack_entry {
struct list_head list;
int n;
};
static LIST_HEAD(mystack);
static void mystack_push(int n) {
struct mystack_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add(&e->list, &mystack);
}
static int mystack_pop(int *np) {
struct mystack_entry *e;
if (list_empty(&mystack))
return -1;
e = list_first_entry(&mystack, struct mystack_entry, list);
if (np != NULL)
*np = e->n;
list_del(&e->list);
kfree(e);
return 0;
}
static void mystack_clean_out(void) {
while (!list_empty(&mystack)) {
mystack_pop(NULL);
}
}
static struct dentry *mylist_dir;
static struct dentry *showfile;
static struct dentry *pushfile;
static struct dentry *popfile;
static char testbuf[1024];
static ssize_t show_read(struct file *f, char __user *buf, size_t len, loff_t *ppos)
{
char *bufp = testbuf;
size_t remain = sizeof(testbuf);
struct mystack_entry *e;
size_t l;
if (list_empty(&mystack))
return simple_read_from_buffer(buf, len, ppos, "\n", 1);
list_for_each_entry(e, &mystack, list) {
int n;
n = snprintf(bufp, remain, "%d ", e->n);
if (n == 0)
break;
bufp += n;
remain -= n;
}
l = strlen(testbuf);
testbuf[l - 1] = '\n';
return simple_read_from_buffer(buf, len, ppos, testbuf, l);
}
static ssize_t push_write(struct file *f, const char __user *buf, size_t len, loff_t *ppos)
{
ssize_t ret;
int n;
ret = simple_write_to_buffer(testbuf, sizeof(testbuf), ppos, buf, len);
if (ret < 0)
return ret;
sscanf(testbuf, "%20d", &n);
mystack_push(n);
return ret;
}
static ssize_t pop_read(struct file *f, char __user *buf, size_t len, loff_t *ppos)
{
int n;
if (*ppos || mystack_pop(&n) == -1)
return 0;
snprintf(testbuf, sizeof(testbuf), "%d\n", n);
return simple_read_from_buffer(buf, len, ppos, testbuf, strlen(testbuf));
}
static struct file_operations show_fops = {
.owner = THIS_MODULE,
.read = show_read,
};
static struct file_operations push_fops = {
.owner = THIS_MODULE,
.write = push_write,
};
static struct file_operations pop_fops = {
.owner = THIS_MODULE,
.read = pop_read,
};
static int mymodule_init(void)
{
mylist_dir = debugfs_create_dir("mystack", NULL);
if (!mylist_dir)
return -ENOMEM;
showfile = debugfs_create_file("show", 0400, mylist_dir, NULL, &show_fops);
if (!showfile)
goto fail;
pushfile = debugfs_create_file("push", 0200, mylist_dir, NULL, &push_fops);
if (!pushfile)
goto fail;
popfile = debugfs_create_file("pop", 0400, mylist_dir, NULL, &pop_fops);
if (!popfile)
goto fail;
return 0;
fail:
debugfs_remove_recursive(mylist_dir);
return -ENOMEM;
}
static void mymodule_exit(void)
{
debugfs_remove_recursive(mylist_dir);
mystack_clean_out();
}
module_init(mymodule_init);
module_exit(mymodule_exit);
コード量は若干多いですが、これまでに学んだdebugfsとlistの使い方を知っていれば、それほど難しくないです。以下にポイントを示します。
- list_empty()によってリストが空かどうかを確認する。空なら1, そうでなければ0を返す
使用例を以下に示します。
root@packer-qemu:/home/vagrant# ls /sys/kernel/debug/mystack ls: cannot access '/sys/kernel/debug/mystack': No such file or directory root@packer-qemu:/home/vagrant# insmod /vagrant/list2.ko root@packer-qemu:/home/vagrant# ls /sys/kernel/debug/mystack pop push show root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/show; for ((i=0;i<5;i++)) ; do echo $i >/sys/kernel/debug/mystack/push; cat /sys/kernel/debug/mystack/show; done 0 1 0 2 1 0 3 2 1 0 4 3 2 1 0 root@packer-qemu:/home/vagrant# for ((i=0;i<5;i++)) ; do cat /sys/kernel/debug/mystack/pop; done 4 3 2 1 0 root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/show root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/pop root@packer-qemu:/home/vagrant#
うまく動いているようです。他にも自分で色々動かしてみて下さい。
重大バグ
既に気づいたかたがいるかもしれませんが、このスタックはサイズに制限が無いので、ユーザから無制限に値をpushできてしまいます。そのたびにカーネル内の対応するデータ構造をメモリ上に確保します。このようなことをすると、カーネルの空きメモリをゼロになるまで食いつぶそうとするため、その過程でいわゆる Out of Memory(OOM)が発生します。そうするとデフォルトではOOM killerというカーネルの処理が走り、カーネルが選んだ適当なプロセスを殺戮してメモリの空き容量を増やそうとします。
次のようなコマンドの実行中に別のshellからVMのシリアルコンソールを覗いた結果を示します。
root@packer-qemu:/home/vagrant# for ((i=0;i=1000000000;i++)) ; do echo $i >/sys/kernel/debug/mystack/push; done```
コマンドを実行してしばらく経つと、シリアルコンソールに次のようなメッセージが表示されます。
$ virsh console elkdat_ktest ... [94417.067862] Kernel panic - not syncing: Out of memory and no killable processes... [94417.067862] [94417.067864] CPU: 0 PID: 1 Comm: systemd Tainted: G W O 4.9.0-ktest #1 [94417.067864] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.9.3-20161025_171302-gandalf 04/01/2014 [94417.067866] ffffbbfa000d2dd8 ffffffffaa3ffa12 ffffffffaae0e500 ffffffffaac802f8 [94417.067867] ffffbbfa000d2e60 ffffffffaa19bfb8 ffff9e7600000008 ffffbbfa000d2e70 [94417.067868] ffffbbfa000d2e08 00000000fd454624 00000000000000b5 0000000000000000 [94417.067869] Call Trace: [94417.067871] [<ffffffffaa3ffa12>] dump_stack+0x63/0x81 [94417.067874] [<ffffffffaa19bfb8>] panic+0xe4/0x22d [94417.067876] [<ffffffffaa1a2e9b>] out_of_memory+0x33b/0x490 [94417.067877] [<ffffffffaa1a82c4>] ... [94417.067988] [<ffffffffaa22f635>] SyS_write+0x55/0xc0 [94417.067990] [<ffffffffaa243159>] ? SyS_ioctl+0x79/0x90 [94417.067992] [<ffffffffaa84a2bb>] entry_SYSCALL_64_fastpath+0x1e/0xad [94417.068363] Kernel Offset: 0x29000000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff) [94417.947136] ---[ end Kernel panic - not syncing: Out of memory and no killable processes...
メモリ大量獲得の真犯人であるmystackはカーネル内のデータ構造なので、いかなるプロセスを削除しようとも空きメモリ量は回復しません。このため、カーネルはどうすることもできなくなり、パニックしています。これはカーネルの処理に問題があるとシステム全体が正しく動作しなくなるという良い例です。この問題の修正については後述の演習として残しておきます。
演習問題
- mystackの長さを10に制限する。要素数が10の時にmystack/ に書き込むとEINVALを返す(mystack/push の書き込みハンドラが -EINVALを返せばよい)
- mystackの要素を数値ではなく文字列(char *)にする。要素ごとの文字列の長さ(strlen()の戻り値)は最長10
mystackを改造してmyqueueというキューを作成する
/sys/kernel/debug/myqueue(以下 myqueue/ と表記)がキューに対応
- 要素は数値
- キューの長さは最長10
- myqueue/show を読むことによって現在のリストの一覧を得られる
- myqueue/queue へ書き込んだ文字列に対応する数値(1つ)をキューの末尾に追加する
- myqueue/dequeue を読むことによってキューの先頭要素を得ると共に、当該要素をキューから削除する
おわりに
今回使ったソースはexample/module/list以下に置いています。実はmystackには、リスト長の問題を解決してなお、排他制御という観点から見て重大な問題があります。次回は排他制御の基本について述べます。その過程でこの問題も解決します。
参考資料
- カーネルソースのinclude/linux/list.h: 本章で紹介したもの以外にも沢山のリスト操作関数が定義されている。名前は”list_”で始まる
- LinuxにおけるOOM発生時の挙動
科学実験のようにスケジューラの挙動を観測する
はじめに
本書の主な対象読者はlinuxを含むOSのプロセススケジューラについて聞いたことがない人や、名前は知っているけど具体的に何をするものかをよく知らない人です。
linux kernelは複数プロセスを同時に動作させる(正確にはさせているように見せかける)ためのプロセススケジューラという機能を持っています。といっても、みなさんがlinuxシステムを使う場合は通常プロセススケジューラを意識しないで済むようになっています。では、あえて意識したい場合、どのような機能なのかを知ってみたい場合はどうすればよいのでしょうか。
kernel機能(ここではプロセススケジューラ)の挙動を明らかにするには、ソースを読む、色々ソース改変しながら動かしてみる1、などが有効です。しかし、ここでは一切ソースを読まずに、ユーザプロセスを使う実験のみによってカーネルの挙動を観測してみます。これは、まるで神様2の作った宇宙の仕組みを解き明かそうとする科学実験のようです。
コンピュータに関する本にはスケジューラについて、
- CPU上で同時に動けるプロセスは一つだけ
- 複数プロセスが実行可能な場合、個々のプロセスを適当な長さの時間(タイムスライスと呼びます)ごとにCPU上で順番に動かしている
などという文言が書いていることが多いですが、殆どの人は知らないか、あるいは何となく耳学問として知っているというだけではないでしょうか。本記事では、この文言を仮説とみなして、それが本当かどうかを自作プログラムを使った実験によって検証してみます。実際に「知っている」だけよりも「やって、確認した」ことによって、linux、ひいてはコンピューターシステムについて、より理解が深まると思います。
実験方法
まずは単一CPU上で、ひたすらCPUを使い続けるプロセスを複数個同時に動かし、その統計情報(ある時点でどのプロセスが動作していたか。及び、それぞれの進捗はどれだけか)を採取します。そのデータの分析によって、上述の仮説が正しいかどうかを検証します。
この目的を達成するために、次のような仕様のプログラムを作成します。
以下の引数を持つ
- n: 同時に動かすプロセス数
- total: 動作させる時間(マイクロ秒単位)
- resol: 1データごとの測定間隔(マイクロ秒単位)
n個のプロセスを同時に動作させ、それらが終了したらプログラム全体も終了する
それぞれのプロセスは次のような動作をする
- totalという時間CPUを使い続けた後に終了する
- resolという時間CPUを使うごとに、ID(0から始まるプロセスごとに固有の数値)、プログラム開始時点からの経過時間(マイクロ秒単位)、進捗(0〜1)を記録する
- 終了時に上記の統計情報を出力する
プログラムのソース
本記事で使用するソースはgithub上に置いています。
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <err.h>
#define NLOOP_FOR_ESTIMATION 10000000000L
static inline long diff_usec(struct timeval before, struct timeval after)
{
return (after.tv_sec * 1000000L + after.tv_usec)
- (before.tv_sec * 1000000L + before.tv_usec);
}
static double loops_per_usec()
{
long i;
struct timeval before, after;
if (gettimeofday(&before, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday(before) failed");
for (i = 0; i < NLOOP_FOR_ESTIMATION; i++)
;
if (gettimeofday(&after, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday(after) failed");
return NLOOP_FOR_ESTIMATION / diff_usec(before, after);
}
static inline void load(int nloop)
{
int i;
for (i = 0; i < nloop; i++)
;
}
static void child_fn(pid_t id, struct timeval *buf, int nrecord, int nloop_per_resol, struct timeval start)
__attribute__ ((noreturn));
static void child_fn(pid_t id, struct timeval *buf, int nrecord, int nloop_per_resol, struct timeval start)
{
int i;
for (i = 0; i < nrecord; i++) {
load(nloop_per_resol);
struct timeval tv;
if (gettimeofday(&tv, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday() failed");
buf[i] = tv;
}
for (i = 0; i < nrecord; i++) {
printf("%d,%ld,%f\n", id, diff_usec(start, buf[i]), (double)(i+1)/nrecord);
}
exit(EXIT_SUCCESS);
}
static void parent_fn(int nproc)
{
int i;
for (i = 0; i < nproc; i++)
wait(NULL);
}
static struct timeval **logbuf;
static pid_t *pids;
int main(int argc, char *argv[])
{
int ret = EXIT_FAILURE;
if (argc < 4) {
fprintf(stderr, "usage: %s <nproc> <total[us]> <resolution[us]>\n", argv[0]);
exit(EXIT_FAILURE);
}
int nproc = atoi(argv[1]);
int total = atoi(argv[2]);
int resol = atoi(argv[3]);
if (nproc < 1) {
fprintf(stderr, "<nproc>(%d) should be >= 1\n", nproc);
exit(EXIT_FAILURE);
}
if (total < 1) {
fprintf(stderr, "<total>(%d) should be >= 1\n", total);
exit(EXIT_FAILURE);
}
if (resol < 1) {
fprintf(stderr, "<resol>(%d) should be >= 1\n", resol);
exit(EXIT_FAILURE);
}
if (total % resol) {
fprintf(stderr, "<total>(%d) should be multiple of <resolution>(%d)\n", total, resol);
exit(EXIT_FAILURE);
}
int nrecord = total / resol;
long pagesize = sysconf(_SC_PAGESIZE);
if (pagesize < 0)
err(EXIT_FAILURE, "sysconf() failed");
logbuf = malloc(nproc * sizeof(struct timeval *));
if (logbuf == NULL)
err(EXIT_FAILURE, "malloc(logbuf) failed");
int i, nallocated;
for (i = 0, nallocated = 0; i < nproc; i++) {
int ret_pma = posix_memalign((void **)&logbuf[i], pagesize, nrecord * sizeof(struct timeval));
if (ret_pma) {
errno = ret;
warn("posix_memalign() failed");
goto free_logbuf;
}
nallocated++;
if (mlock(logbuf[i], nrecord * sizeof(struct timeval))) {
warn("mlock() failed");
goto free_logbuf;
}
}
int nloop_per_resol = (int)(loops_per_usec() * resol);
pids = malloc(nproc * sizeof(pid_t));
if (pids == NULL) {
warn("malloc(pids) failed");
goto free_logbuf;
}
struct timeval start;
if (gettimeofday(&start, NULL) == -1) {
warn("gettimeofday(start) failed");
goto free_logbuf;
}
int ncreated;
for (i = 0, ncreated = 0; i < nproc; i++, ncreated++) {
pids[i] = fork();
if (pids[i] < 0) {
goto wait_children;
} else if (pids[i] == 0) {
// children
child_fn(i, logbuf[i], nrecord, nloop_per_resol, start);
/* shouldn't reach here */
}
}
ret = EXIT_SUCCESS;
// parent
wait_children:
if (ret == EXIT_FAILURE)
for (i = 0; i < ncreated; i++)
if (kill(pids[i], SIGINT) < 0)
warn("kill() failed");
for (i = 0; i < ncreated; i++)
if (wait(NULL) < 0)
warn("wait() failed.");
free_pids:
free(pids);
free_logbuf:
for (i = 0; i < nallocated; i++)
free(logbuf[i]);
free(logbuf);
exit(ret);
}
素直に仕様通りに実装したため、それほど難しいことはしていません。気になるかたのためにポイントをいつくか説明しておきます。
- mlock(2)によってデータを記録するバッファ(logbuf[])の物理メモリ上への貼り付けを強制し(物理メモリ上にlockし)、ページフォールトによる測定誤差を無くしています。
- ユーザ空間からカーネル空間への状態遷移無しに時間を測定できるgettimeofday(2)を用いることによって測定誤差を減らしています。他にもCPUのrdtsc命令などによってさらに誤差を減らすこともできますが、ここでは割愛
- loops_per_usec()では、1マイクロ秒CPUを使うのに必要なループの数を推定しています。適当な数(NLOOP_FOR_ESTIMATION)だけ何もしないループを回すのに要した所要時間を測定し、ループ数をその時間で割ることによって求めます。
なお、本記事はプログラムの実装について学ぶのが主目的ではないので、わからなくても気にする必要はありません。
今回は4CPU(正確には1CPU4コア)環境において、CPU3上でプログラムを同時に1〜4個動作させてみます。個々のプロセスごとに100msだけCPUを使います。その間のデータ測定の間隔は1msです。これを実現するためのスクリプトは次の通りです。
#!/bin/bash
NCPU=$(grep -c processor /proc/cpuinfo)
LASTCPU=$(($NCPU - 1))
PATTERN="1 2 3 4"
TOTAL_US=100000
RESOL_US=1000
for i in ${PATTERN} ; do
taskset --cpu-list ${LASTCPU} ./sched $i ${TOTAL_US} ${RESOL_US} >$i.txt
done
あとは make sched && ./captureによって結果が得られます。以下、注意点を示します。
- makeの際に最適化オプションを付けてしまうと、loops_per_sec()やload()の中のループ処理が、意味の無い処理として削除されてしまうことがあります。これらの処理は、人間から見ると「所定の時間だけCPUを使う」という意味のある処理なのですが、コンパイラからすると「論理的に意味の無い、無くても良い処理」とみなされる恐れがあるということです。このため、最適化はしないでください。
- 上記プログラムの実行中は測定誤差を避けるために、なるべく他のプロセスを実行しないでください3。
実験環境
- ハードウェア
- CPU: Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz x 1 (4 core 1 thread)
- RAM: 8GB
ソフトウェア
OS: 2017/2/2 時点での最新の Debian GNU/Linux stretch
- kernel: 4.8.0-1-amd64
測定結果
私の環境で得られた結果をもとにグラフを作成しました。並列度1〜4のそれぞれについて、
CPU上で動作中のプロセス
x軸: 開始時点からの経過時間[us]
y軸: はプロセスの番号(0〜3)
各プロセスの進捗
x軸: 上記グラフと同じ
- y軸: 進捗(0が何もしていない状態。1が完了状態。単調増加する)
という2つのグラフを描きました。筆者がグラフ作りに不慣れなために見た目がダサいですが、そこはご容赦。
プロセス数1
CPU上で動作中のプロセス

ただ一つ存在するp0が常に動作しています。total引数で指定した通り、およそ100ms後に全ての処理が終わります。これについては、仕事量見積もりの誤差やデータ測定のオーバーヘッドなどの理由によって、ちょうど100ms後にするのはなかなか難しいですが、頑張ればこの誤差はある程度は減らせます。興味のあるかたは後述の参考資料をごらんください。
各プロセスの進捗

p0以外に動作中のプロセスはいないため、進捗は単純に経過時間に比例します。
プロセス数2
CPU上で動作中のプロセス

p0, p1が交互にCPUを使っていることがわかります。全プロセスが同じ長さのタイムスライスを持っていると推測できます。処理完了までの経過時間はプロセス数1の場合のおよそ2倍です。それぞれのプロセスは単一CPUの計算能力を半分づつしか使えないので、これは当然の話です。
各プロセスの進捗

それぞれ自分がCPUを使っている間だけ処理が進捗し、それ以外、つまりCPU上で別のプロセスが動作している間は進捗がありません(グラフ上ではx軸にほぼ平行な線として現れる)。これは1つ上のグラフからなんとなく推測できることです。
また、ややカクカクしていますが、大まかに見るとp0, p1とも、プロセス数1の場合の線の傾きを半分にした直線に似た線になります。仮にそれぞれのプロセスがCPUを使えていない時間が気にならない、気づかない(数mmなどというのは人間にとって非常に小さな時間です)というのであれば、人間には二つのプロセスが同時に動いているように錯覚させられます。
プロセス数3
CPU上で動作中のプロセス

プロセス数2の場合と傾向は同じです。p0->p2->p1の順番にCPU実行権が遷移しています。タイムスライスはプロセス数2の場合に比べて短くなっているようです(これは生データの分析によってわかります)。終了までの経過時間は1プロセスの場合の約3倍です。
各プロセスの進捗

3プロセスになっても2プロセスの場合と傾向は同じです。
プロセス数4
CPU上で動作中のプロセス

これも他の場合と傾向は同じです。p0->p2->p1->p3の順にCPU実行権が遷移しています。タイムスライスはプロセス数3の場合に比べて、さらに短くなっているようです。終了までの経過時間はプロセス数1の場合の約4倍です。
各プロセスの進捗

これも他のものと傾向が同じです。
考察
実験結果から次のようなことがことがわかりました。
- 同時に何個のプロセスが実行可能状態で存在しようとも、1CPU上である瞬間に動作できるプロセスは1つだけ
- 複数プロセスの間でラウンドロビン形式でCPU実行権が移ってゆく
- タイムスライスはプロセス数が増加するほど減少する
スケジューラになじみのないかたがたにとっては、なかなかおもしろいデータだったのではないでしょうか。是非ご自分の環境でも試してみて下さい。さきほども言いましたが、人がやっているのを見るのと自分でやってみるのでは全然理解の深さが変わってきます。
終わりに
本書で実施したことに加えて、次のようなことをするとまた新たな面白い情報が得られます。興味のあるかたは挑戦してみてください。
- プロセス数に応じてタイムスライスがどのように変わるかの法則を明らかにする
- resolの値をタイムスライスより大きな値に増やしてみる
- 複数CPUで実行する: たとえば本記事で使用したtaskset(1)の--cpu-listオプションが使えます。例えば--cpu-list 2,3とすると、プロセスがCPU2,3のどちらかの上でのみ実行できるようになります。また、この場合にはresol毎の情報採取時に、sched_getcpu(3)を用いてプロセスが動作中のCPUの情報を追加採取するとよいでしょう
- nice値を変えたプロセスを動かしてみる
- リアルタイムプロセスで同じことをしてみる: chrt(1)コマンドが使えます
- CPUを使い続けるだけではなく、nanosleep(2)などによってスリープ処理を入れてみる
当初はこれらについては記事に盛り込むつもりでしたが、本記事を書くのが意外と大変だったため、力尽きました。続きは参考資料に挙げた「[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識」に書きました。
実はlinuxのプロセススケジューラはv2.6.23から大規模な書き直しをされており、このバージョン前後で挙動がかなり異なっています。たとえば本記事の実験においてタイムスライスはプロセス数に応じて減少しましたが、古いスケジューラでは別の挙動をします。興味のあるかたは、本記事で使用したプログラムを、古いスケジューラを採用するカーネル(v2.6.22以前。CentOSでいうと5.x以前が使用)で実行して結果を比較してみるのもよいと思います。
最後にもう一点だけ。ユーザ空間からだけでなくカーネルのスケジューラのソースも見ると神様の視点から直接カーネルの内部がわかって楽しいですよ。そこには観測したデータではなく、事実が直接書いています。ようこそカーネルの世界へ。
参考資料
- タスクスケジューラ用のsysctlパラメタ: スケジューラに関するsysctlパラメタに加えてスケジューラそのものの挙動についても少し説明しています
- Linux スケジューラーのコア実装とシステムコール: スケジューラのソースについての解説記事
- RHEL7のパフォーマンスチューニングガイドに記載の推奨設定: 本書に記載したような測定プログラムの精度を下げる敵である外乱(割り込み処理や測定用プロセス以外のプロセス)を減らすための方法について記載しています
- [試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識: プロセススケジューラの章において、複数CPU環境におけるスケジューリングの実験など、本記事の内容をさらに突っ込んだとことを説明しています
ソフトウェアのサポート業務とはどのようなものか
はじめに
ソフトウェアの世界にはいろいろな仕事があります。何も知らない人から見て一番脚光を浴びがちなのが開発者、とくにプログラマーでしょう。スーパープログラマーを題材とした漫画やアニメ、映画はたくさんあります。しかし、それ以外の仕事は実際やってみないと想像しづらいことより、あまり実情が知られていません。本記事ではそれらの中からサポートエンジニアに注目して、この職種がどういうものなのかについて書きました。対象読者は開発者、とくに自分で作ったものを自分ないし近しい人だけが使うという経験しかしていない駆け出しの開発者です。
サポートエンジニアといっても色々なものがありますが、ここではSI企業において顧客システムでトラブルが起きたときにSEの依頼を受けて問題を解決するエンジニア、という極めて単純な定義をしておきます。開発者がサポートエンジニアを兼ねるケースとそうでないケースの両方がありますが、本書ではどちらでもかまいません。
筆者はかつてSI企業において社会インフラを支えるような大きなシステムについてのLinuxカーネルの開発、サポートを数年経験しました。本記事はそんな筆者がこれまでに体験したこと、見聞きしたことをもとに書いています。筆者の経験は非常に狭い範囲についてのものなので本記事の内容が当てはまらない環境はいくらでもあるでしょうが、少なくともサポート経験者の一人からはこう見える、という観点で見ていただけたらと思います。
本記事を書いた動機は次のようなものです。
- サポート業務がなんであるか、どういう魅力があるのかについて知ってほしい
- 開発とサポートが相互に補完し合う、それぞれ別種の能力が必要であることを理解してほしい
- 上記を踏まえて、開発に比べてサポートが簡単な、一歩下のものであるとかいう雰囲気が1あるのを何とかしたい
前置きが長くなってしまいましたが、次節から具体的な話をします。
顧客およびSEの価値観を理解する
顧客およびSEの価値観(以降顧客とSEは価値観を共有しているものとして顧客の価値観と記載)がサポートエンジニアと異なっていることによって両者の会話がまったく成立しないということが多々あります。やや極端ですが、SEであるAさんと、開発者出身で最近サポートエンジニアになったBさんの例を考えてみましょう。二人の価値観は次のようなものです。
- Aさん価値観: トラブルなくサービスを継続できるのが好ましい
- Bさんの価値観: 好きなプログラミング言語を使って美しいコードを書くのが好ましい
すでに嫌な予感がプンプンしていますが、この不一致によって発生するのが以下のような世にも恐ろしい会話です。
- Aさん「先日報告した問題について現状を教えてほしい」
- Bさん「(ソースを見せながら)これはfooクラスのbarというメソッドがO(n)なのでnが増えたときにスケールしないことが問題です」
- Aさん「??? 問題はいつまでに解決する見込みでしょうか」
- Bさん「ここのコードは腐っているので1週間くらいかけて根本的に作り直したほうがいいです。」
- Aさん「なんとか影響を最小限におさえて短期間で仮修正ができないでしょうか」
- Bさん「そんなダサいことはしたくありません」
- Aさん「???」
ここでの問題は、システムのユーザはあくまで顧客であるのに対してBさんが顧客の価値観を無視して自分の好きなことを言っていることにあります。優秀とされるプログラマがサポート業務はまったくできないというのはよくある話ですが、そのうちの少なからぬ数がこれにあてはまります。
このようなことを避けるために、Bさんには相手の立場に立って顧客の価値観を第一に、自分の価値観は第二に考えるという発想の転換が必要でしょう。これがどうしてもできない、やりたくないという人は別の人にサポートを任せるとよいでしょう。ただしそのときに「自分の価値観を理解しないAは程度が低い」というような驕った考え方をするのではなく、「自分はコードは書けるがサポートはできない。自分とサポートエンジニアはお互いに補完し合おう」と考えるほうが建設的でしょう。
システムへの影響は最小限に
あるソフトウェアのバージョンアップによって何らかの問題が発生したとします。ここでは簡単のために前バージョンと現バージョンの間に100コミットあり、かつ、再現手順は明らかになっているものとします。このとき根本原因を知るための愚直ながら確度が高い方法のひとつにbisectというものがあります。具体的には、まず前バージョンから50コミット目で再現試験をして、問題が発生したら次は25コミット目で再現試験を…という手順を繰り返して対数オーダーで根本原因となるコミットを突き止めるという方法です2。
では顧客システムでバイナリサーチを試せるでしょうか。答えはほとんどの場合は否です。なぜかというと顧客システムでソフトウェアのバージョンを入れ替えるということは、そのたびにシステムが停止する、それによって顧客のサービスが停止するということを意味します。したがって、このようなことを何度も試させてくれるという可能性は低いでしょう。その他にも開発環境でしか使えないような性能劣化の激しいログやトレースの有効化などは、そうそう使わせてもらえないでしょう。このため、サポートエンジニアは常に問題の切り分けをするための手段を多く持っておく、および、それらがどのような条件で使えるかを把握しておく必要があります。
依頼は具体的に、数は最小に、意図は明確に
みなさんはご自身がお持ちの何らかの製品のサポートを受けたことが少なからずあると思います。そのときのことを考えてみてください。ただでさえ問題が発生していて面白くない気分なのに次から次へと新たな依頼をされたらどう思うでしょうか。おそらくは段々イライラしてくるのではないでしょうか。これと同じことがコンピュータシステムにおいても言えます。
SEへの依頼は回数が増えれば増えるほど相手の負の感情を増幅させます。それに加えて依頼の意図が不明であればあるほどSEのサポートエンジニアへの不信感が増えます。このようなことをを避けるために、SEへの依頼の数は最小限にして、かつ、それぞれの依頼は何をしたいがために何をしてほしいのかを明確にする必要があります。サポートエンジニアの依頼の裏にある意図を読み取って回答してきてほしいという安易な考え方は捨てましょう。
依頼回数についてもう少し細くしておきます。依頼回数に限りがあるなかで調査を進めるためには次のような方法があります。
- システム稼働時の要所要所でログをとる
- 同、メトリクスを採取する
- システムの異常終了時にコアダンプ(異常終了時のメモリの中身を保持したファイル)をとる
サポートエンジニアには、これらの状況証拠から逆算して根本原因を見つける探偵のような能力が必要になります。それに加えて依頼回数、およびその際の影響範囲を最小限におさえなければならないという制約もあります。この手の能力はプログラミング能力とはまた別種の能力であり、優秀なプログラマがトラブルシューティングは苦手ということはよくあります(その逆も然りです)。
どれも事後に仕掛けて再度再現を試みるのは大変ですので、可能な限り常に採取できるようにしておくとよいでしょう。
ログやメトリクスについては、採取するのは開発者であるものの、どのようなログやメトリクスがあれば調査が楽かはサポートの視点が必要です。このため、開発とサポートは密に連携してサービスレベルの向上に取り組むとよいでしょう。それに加えて開発者はサポートの視点を身につけるために一度はサポート業務を経験するとよいと筆者は考えます。実際筆者は両方経験したことによりソフトウェア技術者として大きく成長できたことを常々実感しています。
記憶ではなく記録をもとに調査する
SEへ問い合わせをする際は可能な限りソフトウェアの出力ベースで話をする必要があります。なぜかというと人は悪意が無くても無意識に嘘をつくからです。一番有名なのは「何もしてないのに壊れた」というやつです。典型的なのは以下のような会話です。
- SE「昨日から問題が発生するようになった」
- サポートエンジニア「問題発生前後で何かしましたか」
- SE「なにもしてない」
- 後日調査に疲れ果てたサポートエンジニア「(ソフトウェアのバージョン変わってるし…)」
このようなことを避けるために、確認はSEをはじめとする関係者の記憶に頼るのではなく、ソフトウェアのログなどの記録に頼るべきでしょう。たとえば上記の問答でいうとサポートエンジニアは「ソフトウェアのアップデートログを見せてください」などのようにするとよかったでしょう。これを踏まえて、システムの状態が変化するときにはどこにどのような記録が残るかについては押さえておくべきでしょう。
サポートが複数階層に分かれる場合
前節まではSEから問題発生時に特定コンポーネントに直接調査依頼が来るという想定でした。しかしシステムがある程度以上の規模になると複数階層になっていることがほとんどです。具体的にはSEが一次サポートエンジニアに調査依頼をすると、そこで切り分けをした上で関係していそうなコンポーネントのサポートエンジニアにさらに調査を振り分ける、というようになります。なぜこのようなことをするかというと、例えばシステムが二つのコンポーネントA,Bから構成されているとして、すべての問題報告がAとB両方のサポートエンジニアに降ってくると効率が悪いからです。
一次サポートエンジニアには開発者、および一つのコンポーネントのサポートエンジニアとはまったく別種の能力が必要になります。まず、特定のコンポーネントに対する深い知識というよりも、守備範囲となる複数のソフトウェアについての浅く広い知識が必要になります3。
一次サポートエンジニアは関係者の数が多いです。SEからの報告をもとに各コンポーネントのサポートに対して依頼をして、回答を得て、場合によっては督促をして、さらにSEに報告して…と、たくさんのタスクを同時並列でこなす必要があります。場合によっては先に進めるためにできることがなくなったように見える状態で関係者全員で協議する会を設けて調整をする必要も出てくるでしょう。
わたしは一次サポートエンジニアの経験は無いので確たることは言えませんが、サポートエンジニアをやるとして、システムのより広い範囲を見渡したい、そこで発生する物事の中心にいるハブになりたいようなかたは一次サポートが向いているのではないかと思います。
おわりに
サポートエンジニアは問題発生時に何が起きたかを証拠をもとに仮説を立ててそれを検証していく探偵のようなことを主にやりたい人には魅力的だと思います。また、サポートエンジニアを体験することによって、ソフトウェアを開発するときに何に気を付ければ問題解決が早まるか、および解決できる確率が高まるかということを身をもって知れるため、開発者として一皮むけるためにも有用です。
この記事を読んでサポートエンジニアがどのようなものであるのかがわかってくれる人、および自分もやってみようと思ってくれる人が増えることを願っています。また、問題発生時にSE、サポートエンジニア、開発者が一丸となって建設的に解決をめざすケースが増えることを祈っています。
たのしく学ぶLinuxカーネル開発(第一回): `rm -rf /`実行時にカーネルパニックさせる
はじめに
Linuxカーネル開発を学ぶためにhello worldモジュールからはじめて少しづつ強化する記事を過去にいくつか書きました。これはちゃんとやれば身に付くことは身に付くのですが、非常に地味なので、よほどカーネルに興味を持っている人以外には退屈でしょう。そこで、目的をもって特定の機能をカーネルならではの方法で実現する記事を書けば面白いのでは…となったのでここに初回を書くことにしました。
対象読者はCライクなプログラミング言語での開発経験がある人です。Cのポインタがわかればなおよし。もしできればOSカーネルについての基本的な知識も欲しいです。
背景
UNIXが誕生してから現在に至るまでrm -rf /によって全ファイルをぶっ飛ばす事件が後をたちません。GNUのcoreutilsに入っているrmではルートディレクトリ("/")への操作を特別扱いして容易に悲劇を起こさなくするpreserve-rootというデフォルトで有効になるオプションもあります。しかし人間とはこういうときにもこの機能を無効にする--no-preserve-rootをうっかり付けててしまうのです。
そこでユーザがrm -rf /を実行しようとするとカーネルパニックさせる(Windowsでいうところのブルースクリーンを出す)フェイルセーフ機能を作ることにしました。
対象とするカーネル
- linux v5.3
このカーネルのソースコードは以下コマンドによって取得できます。
$ git clone -b v5.3 --depth 1 https://github.com/torvalds/linux ... # 数GBのディスク容量を消費しますので、ご注意ください $ git checkout v5.3 ... $
変更点
この機能の変更点を示すパッチファイル0001-panic-if-user-tries-to-run-rm-rf.patchの中身は次の通りです(内容は後で説明します)。ライセンスはGPL v2です。
From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001 From: Satoru Takeuchi <satoru.takeuchi@gmail.com> Date: Sun, 6 Oct 2019 15:53:34 +0000 Subject: [PATCH] panic if user tries to run rm -rf / --- fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++ 1 file changed, 37 insertions(+) diff --git a/fs/exec.c b/fs/exec.c index f7f6a140856a..8d2c1441b64c 100644 --- a/fs/exec.c +++ b/fs/exec.c @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename, if (retval < 0) goto out; + // Panic if user tries to execute `rm -rf /` + if (bprm->argc >= 3) { + struct page *page; + char *kaddr; + char rm_rf_root_str[] = "rm\0-rf\0/"; + char buf[sizeof(rm_rf_root_str)]; + int bytes_to_copy; + unsigned long offset; + + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE); + page = get_arg_page(bprm, bprm->p, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + offset = bprm->p % PAGE_SIZE; + memcpy(buf, kaddr + offset, bytes_to_copy); + kunmap(page); + put_arg_page(page); + + if (bytes_to_copy < sizeof(rm_rf_root_str)) { + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy); + kunmap(page); + put_arg_page(page); + } + + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str))) + panic("`rm -rf /` is detected"); + } + would_dump(bprm, bprm->file); retval = exec_binprm(bprm); -- 2.17.1
動かし方
最初に一点注意。この機能は壊してもいいVM上でやりましょう。動作確認テストが失敗すると全ファイルがぶっ飛びかねませんし、成功してもダーティなページキャッシュに乗っているデータは失うことになります。
まずは次のようにパッチファイルを適用した上でビルド、インストール、再起動します。
$ git apply 0001-panic-if-user-tries-to-run-rm-rf.patch ... # 機能追加に必要なパッチを当てる $ sudo apt install kernel-package flex bison libssl-dev ... # カーネルビルドに必要なパッケージをインストール $ make localmodconfig ... # ビルドのための設定をする。何か聞かれたらENTERを押しまくる $ make -j$(grep -c processor /proc/cpuinfo) ... # ビルドする $ sudo make modules_install && make install ... # 新しいカーネルとそのモジュールをインストールする $ sudo /sbin/reboot # GRUBで現在起動中のものなど特定のカーネルを次回起動するようになっている場合は適宜修正してください
再起動後にカーネルバージョンが変わっていることを確認します。
$ uname -r 5.3.0+ $
5.3.0+となっていれば成功です。最後の"+"はカスタムカーネルのときに勝手に付与されます。
最後に例のコマンドを実行します。
$ rm -rf /
これで応答が戻ってこなければ成功です。マシンのコンソールを見ている場合はパニック時のカーネルログが見られます。GUI上の端末エミュレータあるいはssh経由でコマンドを叩いた場合は単に画面が停止したように見えるでしょう。
参考までにわたしの環境での実行結果を載せておきます。
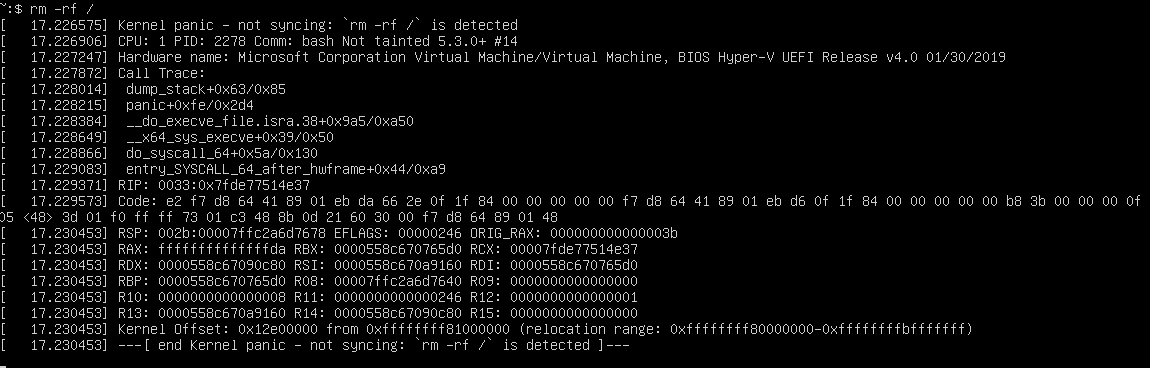
この機能はrm -rf /を誰が実行したかなどというものは考えておらず、ルートディレクトリ以下のファイルを消す権限が無い一般ユーザがこのコマンドを実行しても容赦なくカーネルパニックを起こしますのでご注意ください。
この後はマシンを再起動させて、必要ならば本記事によってインストールしたカーネルを削除したり、GRUBが使うデフォルトカーネルの変更をしたりしてください。
パッチの解説
まずパッチを当てる前のコードについて簡単に説明しておきます。
- ユーザプロセスが新規プログラムを実行しようとexecve()システムコールを呼ぶ
- カーネル内の上記システムコールを処理するハンドラ関数が動作しはじめて、その過程でパッチの中にもある__do_execve_file()関数を呼ぶ
- execve()システムコールの実処理をする。現在動作中のプロセスを新しいプログラムで置き換えて、当該プログラムのエントリポイントから実行開始
このパッチは、3と4の間に、ユーザから渡されたexecve()システムコールの引数がrm -rf /であればカーネルパニックさせる処理を追加します。
ではパッチに行番号を振って説明します。
1 From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001
2 From: Satoru Takeuchi <satoru.takeuchi@gmail.com>
3 Date: Sun, 6 Oct 2019 15:53:34 +0000
4 Subject: [PATCH] panic if user tries to run rm -rf /
5
6 ---
7 fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++
8 1 file changed, 37 insertions(+)
9
10 diff --git a/fs/exec.c b/fs/exec.c
11 index f7f6a140856a..8d2c1441b64c 100644
12 --- a/fs/exec.c
13 +++ b/fs/exec.c
14 @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename,
15 if (retval < 0)
16 goto out;
17
18 + // Panic if user tries to execute `rm -rf /`
19 + if (bprm->argc >= 3) {
20 + struct page *page;
21 + char *kaddr;
22 + char rm_rf_root_str[] = "rm\0-rf\0/";
23 + char buf[sizeof(rm_rf_root_str)];
24 + int bytes_to_copy;
25 + unsigned long offset;
26 +
27 + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE);
28 + page = get_arg_page(bprm, bprm->p, 0);
29 + if (!page) {
30 + retval = -EFAULT;
31 + goto out;
32 + }
33 + kaddr = kmap(page);
34 + offset = bprm->p % PAGE_SIZE;
35 + memcpy(buf, kaddr + offset, bytes_to_copy);
36 + kunmap(page);
37 + put_arg_page(page);
38 +
39 + if (bytes_to_copy < sizeof(rm_rf_root_str)) {
40 + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0);
41 + if (!page) {
42 + retval = -EFAULT;
43 + goto out;
44 + }
45 + kaddr = kmap(page);
46 + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy);
47 + kunmap(page);
48 + put_arg_page(page);
49 + }
50 +
51 + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str)))
52 + panic("`rm -rf /` is detected");
53 + }
54 +
55 would_dump(bprm, bprm->file);
56
57 retval = exec_binprm(bprm);
58 --
59 2.17.1
60
17行目の時点でexecve()の引数はカーネルのメモリに保存されています。ここからが本パッチの変更がはじまります。
検出したいコマンドはrm -rf /であり、かつ、このときの引数の数は3です。これに加えてbprm->argcにはexecve()に渡された引数の数が入っています。よってbprm->argc >= 3という条件のif文によって関係ないコマンド実行を弾いています。べつに>=ではなく==でもよかったのですが、rm -rf / fooとかやっても(このときの引数の数は4)ひどいことになるのには変わりがないのでこうしました。
コマンドライン引数はカーネルメモリ内の所定領域に、各引数をNULL文字('\0')で区切ったデータとして配置されています。たとえばechoコマンドにhelloという文字列を引数として実行した場合は"echo\0hello"というデータになります。コマンド名も引数の一つということに注意してください。rm -rf /の場合は"rm\0-rf\0/"になっているはずです。前述のif文の中身では22行目に「こうあるべき」なデータを置いて、それと実際の引数の値を51行目において比較して、マッチすれば52行目においてカーネルパニックさせています。
カーネルメモリ内からデータをとってくるのが少々やっかいです。これは27~49行目に対応します。必要とするデータはメモリ上の1ないし2ページ(CPUが仮想記憶という機能によってメモリを管理する単位。x86_64アーキテクチャにおいては4KB)にまたがって存在しています。殆どの場合は1ページに収まります。この場合は27行目から37行目だけで終わりです。2ページにまたがる場合は39行目から49行目を実行します。ここではデータが1ページにおさまっている場合についてのみ書きます。
27~37行目はそれぞれ次のような意味を持ちます。
- 27行目: カーネルメモリからもってくるデータのサイズ。データが一ページに収まる場合は9バイト
- 28~32行目: データが入っているページを指すpage構造体と呼ばれるデータを得る、およびそのエラー処理をする。このpage構造体は37行目において解放する
- 33行目: ページ構造体が示すページのアドレスを得る。kmap()によって得たアドレスは36行目のように対応するkunmap()を呼ぶのがお約束
- 34,35行目: 必要なデータをbufにコピー
駆け足で説明しましたがとりあえずフィーリングで読んでみてなんとなくわかればいいと思います。
おわりに
第一回と書きましたが、二回目以降があるかどうかは記事への反響と私のやる気次第です。
自作OSとかLinuxカーネルについて役立った本
はじめに
なんらかの理由によってOSやOSカーネルに興味を持つ人は多々います。しかし、その次のステップとしてどんな本を読めばいいんだろうと思っている人はこれまたいっぱいいます。そこで、長年Linuxカーネルにかかわってきた筆者がこれまでに読んでよかったと思うものについてここの列挙しました。紹介するのは本だけであって、記事は省いています。もう一点、筆者が書いたものは省いています。
OSそのものに興味を持った人は、その後に興味の方向が次のような二つに分かれることが多いと筆者は考えています。
- オレオレOSを作りたい
- 既存のOSを改造したい
この仮説をもとに、それぞれについて筆者がかつて真面目に読んだ本の中から「自作OS」および「Linuxカーネル」というキーワードでよかったものを挙げておきます。Linux以外の既存OSについては語れるほどの知識はないので書いてません。
筆者について
本の良し悪しは人によってさまざまなので、筆者がどういうスキルセット、好みを持った人なのかを最初に書いておきます。わたしにとっての良書はみなさんにとっての悪書かもしれません。
- 3年くらい前まで10年以上Linuxカーネル開発、サポートをしていた
- 最近は枯れているdistributionカーネルのトラブルシューティングが中心。最新のカーネルについてはたまに興味のある最新機能を評価したりパッチ投げたりしてるだけ
- 技術書は要点だけ説明していて後は自分でやってね、という本が好み
- 分厚くて記述の粒度が細かい本は苦手
- 文字より図やグラフを多用した説明を好む
自作OS本
30日でできる! OS自作入門
この界隈で一番有名な本。通称「30日本」。ブート処理を実装して画面を出してその他諸々やって、後は好きなようにしてね!というやつです。この本当に好きなようにした人が多くて本書をきっかけとして多数のオレオレOSが生み出されました。
本の中のかなり早い時期にWindowsのような画面を出して見た目に訴えようとしたり懇切丁寧な書き方にしていたりと、「なんとか最後まで読んでもらおう」という気配りがされていますので、やる気さえあれば挫折率は低いかと。この手の本は「書いてることは合ってるし、これを読み通せばOSを作れるようになるんだろうけど読み通すのが非常につらい」というものが多いので、読んだ当時は非常にびっくりしました。本書を小学生のときに読んでそのままOSオタクになった人たちもいるので小学生でも読めるのかもしれません。
長所はそのまま短所にもなります。いわゆる世間一般でいうOSよりかなり機能が絞り込まれているので、この本を読んだ後は他の本によってさらにステップアップを目指すことになるでしょう。
12ステップで作る組込みOS自作入門
その名の通り組み込みOSを作るための本です。ネット経由で買える安い組み込みボード上に簡単なOSを書いています。作ったときの見た目の派手さは30日本に軍配が上がりますが、こっちのほうが一般にイメージされているOSに近いです。「コンソールに文字出せた!」ということで喜べる人はこっちのほうがいいかもしれません(私は30日本よりもこっちのほうが好きです)。
筆者は本書を見たときにPC上に簡単なOSを実装できる程度の知識はあったものの、それ以外については全く知識が無かったので、「なるほど組み込みボードはPCとこんな風に違うのね」と非常に興味深く読んだと記憶しています。
オペレーティングシステム 第3版
いわゆるタネンバウム本です。5000行くらいでUNIX、Linuxっぽいカーネルを実装しています(「Linuxっぽい」とかいうとタネンバウム先生に怒られそうですが、読者目線であえてこう書いています)。OSとは何であるか、昔はこうであったなどのトリビアも非常に楽しめました。ただしけっこう記述がお堅いのと物理的にデカいのが難点です。
真面目に読みこなすと自作カーネルの上でUnix系OSのコマンドが動かせるようになるので、けっこう感動すると思います。
最後にひとつ。ネット上には「タネンバウム本は古すぎる」という記載が多々ありますが、それらは主に旧版に対する指摘です。三版の内容はけっこうモダンです。
Linuxカーネル
最初に言っておくと私が紹介する本はすべてかなり古いです。なぜなら私がLinuxカーネルの本を積極的に探してたのは数年前までで、その後はLKML(Linux開発の中心となっているメーリングリスト)を追ったり、何かあれば直接ソース見たりしてたので、新しめの本がどうかは知らないからです。ではこれから紹介する本が役立たないかというと決してそうではないと思います。たしかに実装がガラっとかわってしまっているものもあるのですが、変わっていないところも多々あるので、これらは現在のカーネルを理解するのにも非常によい助けになるはずです。
Linux Kernel Development
カーネルとは何か、カーネル開発とは何か、ユーザプログラム開発と何が違うのかをざっと説明した後にLinuxの実装について細かくソースの説明ではなくコアとなる構造体やロジックについて述べています。平易で読みやすくてそれほど分厚くないというのもポイント高いです。
わたしはこの本でLinuxカーネルに入門しました。カーネルとは何かというのを概念的にはざっと知っていたものの具体的にはどんなものかわかっていなかった、という本記事の読者のような状態で読んだところ、十分に理解できたと記憶しています。とてもいい本です。
詳解Linuxカーネル
世間的に「Linuxカーネルといえばこれ」という本。いろんなことを事細かに説明してあるので、概要より詳細を知りたいという人にはいいと思います。まじめに前から順番に読むというよりは「この関数は何をするためのものだろう」と目次を引いて調べる…というように辞書的に使うのがよいかもしれません。
細かいところはどうでもいいという人はソースを一行一行説明しているようなところをさくっと読み飛ばすと実はそんなに読むのに時間はかかりません。
Linuxカーネル2.6解読室
説明の粒度的にはLinux Kernel Developmentと詳解Linuxカーネルの間にあるような本です。個人的にはLinux Kernel Development, Linuxカーネル2.6解読室、詳解Linuxカーネルの順番で読むとよいと思います。
私は駆け出しのカーネルエンジニアのときにずいぶんと本書のお世話になりました。最大の問題は絶版になっているのか新刊が手に入らないことでしょう。中古高い。
おわりに
これまでに述べたものはあくまで数年間この手の本を真面目に読んでいない筆者が良いと思ったものなので、今はもっといいのがあると思います。「わたしはこの本が好きだ!」とかいうのがあればコメント欄に書いていただけると私やこの記事を見た人が喜ぶかもしれません。一つ確実に言えるのは、少なくともLinuxカーネルについては現在(昔もだけど)日本語より英語の情報が圧倒的に多いことです。まじめに取り組みたいなら英語を恐れるなかれ、です。
システムを一時的に停止させるカーネルモジュール
はじめに
システムを一時的に停止させるstop-machineというカーネルモジュールを紹介します。ソースはここにあります。使いかたはREADMEを見てもらえればわかります。
Ubuntu 18.04上でlinuxカーネル4.18.0-18-genericを起動させた状態で動作検証をしました。
現在の実装ではカーネルモジュールをロードしてから5秒だけシステムを停止させます。ソースの中のSTOP_MSECS定数を変更すればミリ秒単位で一時停止させる時間を変更可能です1。ここでいう停止とは次のようなものです。
- あらゆるプロセスが動作できない
- あらゆるデバイスが動けない。正確にいうとデバイスから割り込みが上がってきても停止が解除するまで待たせられる。
- 上記に伴いストレージI/O、ネットワークI/Oが動かないし、ユーザからの操作も一切付けつけない
考えられる用途
このモジュールは、システムが応答しなくなったような状態でソフトウェアがどう振舞うかというテストを簡単にできるので便利です。
例
本当に止まっているかを確認してみましょう。まずはモジュールをロードするのとは別の端末を開いて、1秒ごとに現在時刻を表示するスクリプトを動かします。
$ for ((;;)) ; do sleep 1 ; date -R ; done Sat, 04 May 2019 09:40:27 +0900 Sat, 04 May 2019 09:40:28 +0900 Sat, 04 May 2019 09:40:29 +0900 Sat, 04 May 2019 09:40:30 +0900 Sat, 04 May 2019 09:40:31 +0900 ...
この状態でもとの端末に戻ってモジュールをロードすると、約5秒後にshellのプロンプトが出てきます。
$ sudo insmod stop-machine.ko $ # insmodコマンドを発行してから約5秒後にこのプロンプトが出てくる
一秒ごとに現在時刻を出力していた端末では5秒間時間が飛んだように見えていることがわかります(以下実行例の☆1から☆2の間)。
... Sat, 04 May 2019 09:44:38 +0900 Sat, 04 May 2019 09:44:39 +0900 Sat, 04 May 2019 09:44:40 +0900 Sat, 04 May 2019 09:44:41 +0900 Sat, 04 May 2019 09:44:42 +0900 Sat, 04 May 2019 09:44:43 +0900 Sat, 04 May 2019 09:44:44 +0900 ☆1 Sat, 04 May 2019 09:44:49 +0900 ☆2 Sat, 04 May 2019 09:44:50 +0900 Sat, 04 May 2019 09:44:51 +0900 ...
最後に現在時刻を出していた端末を閉じた上で、モジュールを以下のようにアンロードしておきましょう。
$ sudo rmmod stop-machine $
実装のはなし
このモジュールは、linuxカーネル内のstop_machine()という関数を使っています。この関数は第一引数によってシステム停止中に実行するハンドラを、第二引数によってこのハンドラ実行時に渡される引数を、第三引数によって「どのCPUを停止させるか」を決めます(NULLにすれば全CPU)。stop_machine()関数はカーネル内で他の処理に一切割り込まれたくない処理において使われます。このモジュールにおいてはハンドラの中で1秒だけCPUを使うような無限ループを全CPU上で回しています。
stop_machine関数について興味のあるかたはソース2をごらんください。この記事を書いた後にakachochinさんが大変よい記事を書いてくださったのでまずはこちらを読むといいと思います。
なんでもかんでも「バグ」ってひとくくりにしないで
はじめに
プログラマがソフトウェアを作るとユーザがつきます。ユーザがそのソフトウェアを使っていて何らかの問題が発生すると「このソフトはバグってる、直して!」と言われることがままあります。それに対して「いや、仕様だから」と突っぱねられることがあります。その後お互いの意見が「バグだ!」「いいや仕様だ!」と平行線になってお互いモヤモヤのまま終わるというのはよくある話です。
なぜこういうことが起きるかというと、原因の一つは「問題」イコール「バグ」という短絡的な考え方です。とくにソフトウェアを作ったり使ったりした経験が浅い人がこうなる傾向があると推測しています。このような食い違いは「要件」「仕様」と「実装」という言葉の意味を理解していればある程度解決できます。本書はこれらの用語について実例を挙げて簡単に紹介します。
注意点
- 本記事では要件や仕様を定義することが前提となっていますが、とくにユーザと開発者が同じような場合にはこれらが明確でないことがままあります。OSSにおけるこのあたりの感覚についてはこの記事が非常に参考になります。興味のあるかたはごらんください
- 原因がわかったときにその責任がどこにあるかについて。たとえば原因がソフトウェアの誤りであることがわかっても、たとえばGPLのように「無保証」と銘打っているライセンスを採用しているソフトウェアについては「ここバグってるからソフトウェアを直して」とユーザが言っても開発者には直す責任はありません(運が良ければ直してくれることもあります)。この場合は自分で修正を作って開発者に提供して直してもらうなどの対処が考えられます。このあたりは本記事のスコープから外れますのでこれ以上は述べません。今後「開発者に責任がある」と書いている場合は、無保証のソフトウェアについては状況が違うと考えてください。
- 本記事に書いてあるようなことは百も承知で、自分あるいは自分の所属する組織に有利になるようにゴネる人もいますが、そういうケースはここでは扱いません。同じく、責任が誰にあるかは明確であってもユーザと開発者の力関係によって誰に責任があるのかが政治的に決まる、場合によっては両者の意見の相違によって裁判沙汰になることもありますが、それについてもここでは扱いません。
要件
ソフトウェアを作る際には、最初に「いったどういうソフトウェアを作りたいのか」という要件を定義します。ここでは次のような要件があるとします。
- ある組織に複数の人が属している
- 個々人について名前と年齢という情報が並べられた表を管理したい
- 年齢をキーとして組織に属する人すべての情報を昇順に表示したい
この要件定義はユーザ(自分自身かもしれません)の思いを反映しているものとします1。
仕様
仕様とはソフトウェアのあるべき姿です。ここでは個々人の情報を以下のstruct personという構造体を使って扱うものとします。
struct person { char *name; int age; }
ここでageは必ず0以上の数値にしなければならないとします。
ここからはstruct personという構造体の配列をソートするsort()という関数の仕様を次のように定義したとします。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて昇順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のaはa[0]->age <= a[1]->age <= ... <= a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
仕様の誤り
ここでsort()関数の仕様が前節において述べたものではなく次のようなものだったとします。もとの仕様と違うところは太字で書いています。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて降順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のaはa[0]->age >= a[1]->age >= ... >= a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上。lenが0未満の場合の動作は未定義- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
要件によるとsort()関数は配列aを昇順にソートすべきでしたが、ここでは降順にソートしてしまっています。このように要件に沿っていない場合は開発者が作った仕様が誤っているという問題が発生したといえます。誰に責任があるかは契約次第なのですが、ユーザが仕様にOKを出して全責任を負う、という契約であればユーザの責任ですし、開発者が仕様を自由に決めてよくて、かつ、開発者が責任を負うという契約の場合は開発者の責任となります。
仕様の誤りには他にも次のようなものが考えられます。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて降順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のa[]はa[0]->age < a[1]->age < ... < a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上。lenが0未満の場合の動作は未定義- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
こちらは個々人の年齢が同じ場合に仕様を満たせないため、これも仕様が誤っていると言えます。
実装
ではsort()関数の実装について考えます。ここでいう実装とはsort()関数を仕様に定められた通りに動くようにコード化することです。仕様を満たしさえすればどういう実装にしてもかまいません。なお、ここでは実装のコードそのものは重要ではないので考えません。
実装の誤り
sort()関数の実装が、a[]を降順にソートしてしまうものだった場合はどう考えればいいでしょうか。これは実装が仕様を満たしていないので、開発者による実装の誤りが発生した問題と言えます。責任の所在については、たとえばユーザが仕様にOKを出して全責任を負う、という契約であればユーザの責任ですし、開発者が仕様を自由に決めてよくて、かつ、開発者が責任を負うという契約の場合は開発者の責任となります。
使用方法の誤り
sort()関数の仕様も実装も正しいとします。ではこれで問題が発生しないかというとそんなことはありません。たとえばユーザがデータ入力を間違えており、a[]の中にageが-10の要素があったとします。この場合、sort()関数はエラーを示す1を返します。ここでユーザが「なぜソートされていないんだ、これは問題だ!バグだ!」ということはよくあるのですが、これはsort()関数自体は仕様通りに1を返しているだけなのでユーザが使用方法を誤っているといえます。
実装依存のふるまい
sort()関数の実装に使われるソートアルゴリズムには安定ソートと不安定ソートという二種類のものがあります。これらの意味については本記事のスコープを外れるのでwikipediaの記事などをご覧ください。sort()関数の仕様を見ると、この関数が安定ソートなのかどうかということは定められていません。このような場合に実装においてどちらの種類のアルゴリズムにするかは開発者にゆだねられています。
ここでユーザが「ソートといえば安定ソートだろ」という想定でこのソフトウエアを使って思い通りにならなかった場合に「これは問題だ!バグだ!」ということがありますが、これについては安定ソートか否かは仕様によって未定義なので責任は通常ユーザにあります。
バージョンアップと実装依存
たまたまsort()関数が安定ソートであり、かつ、ソフトウェアのバージョンアップに伴いsort()関数の実装が変わって不安定ソートにする場合はどのように扱えばよいでしょうか。これについては考え方が色々ありますが、原理原則からいうと未定義の動作がどうなろうとこれは問題ありません。ただし特別な理由がない限りこういうことは避けるほうがよいでしょう。文化によってはこの手の変更が決して許されないこともあります。
おわりに
ここまでみてくださったかたがたに感謝いたします。これを読み切ったかたの多くは何らかの形で本記事冒頭で述べたような状況に遭遇したことがあるのではないかと思います。それが作る側であったとしても使う側であったとしても、言葉の定義があやふやなことによる不幸な話の食い違いがこの記事によって多少なりとも減ることを祈ります。
-
とくにユーザと開発者が違う人の場合に要件定義がそもそも間違っていることも多々ありますが、それについては割愛します↩