たのしく学ぶLinuxカーネル開発(第一回): `rm -rf /`実行時にカーネルパニックさせる
はじめに
Linuxカーネル開発を学ぶためにhello worldモジュールからはじめて少しづつ強化する記事を過去にいくつか書きました。これはちゃんとやれば身に付くことは身に付くのですが、非常に地味なので、よほどカーネルに興味を持っている人以外には退屈でしょう。そこで、目的をもって特定の機能をカーネルならではの方法で実現する記事を書けば面白いのでは…となったのでここに初回を書くことにしました。
対象読者はCライクなプログラミング言語での開発経験がある人です。Cのポインタがわかればなおよし。もしできればOSカーネルについての基本的な知識も欲しいです。
背景
UNIXが誕生してから現在に至るまでrm -rf /によって全ファイルをぶっ飛ばす事件が後をたちません。GNUのcoreutilsに入っているrmではルートディレクトリ("/")への操作を特別扱いして容易に悲劇を起こさなくするpreserve-rootというデフォルトで有効になるオプションもあります。しかし人間とはこういうときにもこの機能を無効にする--no-preserve-rootをうっかり付けててしまうのです。
そこでユーザがrm -rf /を実行しようとするとカーネルパニックさせる(Windowsでいうところのブルースクリーンを出す)フェイルセーフ機能を作ることにしました。
対象とするカーネル
- linux v5.3
このカーネルのソースコードは以下コマンドによって取得できます。
$ git clone -b v5.3 --depth 1 https://github.com/torvalds/linux ... # 数GBのディスク容量を消費しますので、ご注意ください $ git checkout v5.3 ... $
変更点
この機能の変更点を示すパッチファイル0001-panic-if-user-tries-to-run-rm-rf.patchの中身は次の通りです(内容は後で説明します)。ライセンスはGPL v2です。
From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001 From: Satoru Takeuchi <satoru.takeuchi@gmail.com> Date: Sun, 6 Oct 2019 15:53:34 +0000 Subject: [PATCH] panic if user tries to run rm -rf / --- fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++ 1 file changed, 37 insertions(+) diff --git a/fs/exec.c b/fs/exec.c index f7f6a140856a..8d2c1441b64c 100644 --- a/fs/exec.c +++ b/fs/exec.c @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename, if (retval < 0) goto out; + // Panic if user tries to execute `rm -rf /` + if (bprm->argc >= 3) { + struct page *page; + char *kaddr; + char rm_rf_root_str[] = "rm\0-rf\0/"; + char buf[sizeof(rm_rf_root_str)]; + int bytes_to_copy; + unsigned long offset; + + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE); + page = get_arg_page(bprm, bprm->p, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + offset = bprm->p % PAGE_SIZE; + memcpy(buf, kaddr + offset, bytes_to_copy); + kunmap(page); + put_arg_page(page); + + if (bytes_to_copy < sizeof(rm_rf_root_str)) { + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy); + kunmap(page); + put_arg_page(page); + } + + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str))) + panic("`rm -rf /` is detected"); + } + would_dump(bprm, bprm->file); retval = exec_binprm(bprm); -- 2.17.1
動かし方
最初に一点注意。この機能は壊してもいいVM上でやりましょう。動作確認テストが失敗すると全ファイルがぶっ飛びかねませんし、成功してもダーティなページキャッシュに乗っているデータは失うことになります。
まずは次のようにパッチファイルを適用した上でビルド、インストール、再起動します。
$ git apply 0001-panic-if-user-tries-to-run-rm-rf.patch ... # 機能追加に必要なパッチを当てる $ sudo apt install kernel-package flex bison libssl-dev ... # カーネルビルドに必要なパッケージをインストール $ make localmodconfig ... # ビルドのための設定をする。何か聞かれたらENTERを押しまくる $ make -j$(grep -c processor /proc/cpuinfo) ... # ビルドする $ sudo make modules_install && make install ... # 新しいカーネルとそのモジュールをインストールする $ sudo /sbin/reboot # GRUBで現在起動中のものなど特定のカーネルを次回起動するようになっている場合は適宜修正してください
再起動後にカーネルバージョンが変わっていることを確認します。
$ uname -r 5.3.0+ $
5.3.0+となっていれば成功です。最後の"+"はカスタムカーネルのときに勝手に付与されます。
最後に例のコマンドを実行します。
$ rm -rf /
これで応答が戻ってこなければ成功です。マシンのコンソールを見ている場合はパニック時のカーネルログが見られます。GUI上の端末エミュレータあるいはssh経由でコマンドを叩いた場合は単に画面が停止したように見えるでしょう。
参考までにわたしの環境での実行結果を載せておきます。
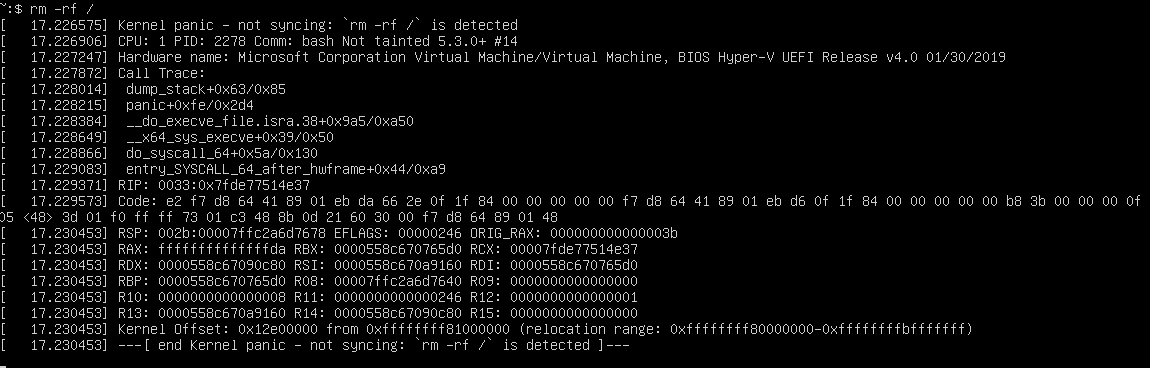
この機能はrm -rf /を誰が実行したかなどというものは考えておらず、ルートディレクトリ以下のファイルを消す権限が無い一般ユーザがこのコマンドを実行しても容赦なくカーネルパニックを起こしますのでご注意ください。
この後はマシンを再起動させて、必要ならば本記事によってインストールしたカーネルを削除したり、GRUBが使うデフォルトカーネルの変更をしたりしてください。
パッチの解説
まずパッチを当てる前のコードについて簡単に説明しておきます。
- ユーザプロセスが新規プログラムを実行しようとexecve()システムコールを呼ぶ
- カーネル内の上記システムコールを処理するハンドラ関数が動作しはじめて、その過程でパッチの中にもある__do_execve_file()関数を呼ぶ
- execve()システムコールの実処理をする。現在動作中のプロセスを新しいプログラムで置き換えて、当該プログラムのエントリポイントから実行開始
このパッチは、3と4の間に、ユーザから渡されたexecve()システムコールの引数がrm -rf /であればカーネルパニックさせる処理を追加します。
ではパッチに行番号を振って説明します。
1 From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001
2 From: Satoru Takeuchi <satoru.takeuchi@gmail.com>
3 Date: Sun, 6 Oct 2019 15:53:34 +0000
4 Subject: [PATCH] panic if user tries to run rm -rf /
5
6 ---
7 fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++
8 1 file changed, 37 insertions(+)
9
10 diff --git a/fs/exec.c b/fs/exec.c
11 index f7f6a140856a..8d2c1441b64c 100644
12 --- a/fs/exec.c
13 +++ b/fs/exec.c
14 @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename,
15 if (retval < 0)
16 goto out;
17
18 + // Panic if user tries to execute `rm -rf /`
19 + if (bprm->argc >= 3) {
20 + struct page *page;
21 + char *kaddr;
22 + char rm_rf_root_str[] = "rm\0-rf\0/";
23 + char buf[sizeof(rm_rf_root_str)];
24 + int bytes_to_copy;
25 + unsigned long offset;
26 +
27 + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE);
28 + page = get_arg_page(bprm, bprm->p, 0);
29 + if (!page) {
30 + retval = -EFAULT;
31 + goto out;
32 + }
33 + kaddr = kmap(page);
34 + offset = bprm->p % PAGE_SIZE;
35 + memcpy(buf, kaddr + offset, bytes_to_copy);
36 + kunmap(page);
37 + put_arg_page(page);
38 +
39 + if (bytes_to_copy < sizeof(rm_rf_root_str)) {
40 + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0);
41 + if (!page) {
42 + retval = -EFAULT;
43 + goto out;
44 + }
45 + kaddr = kmap(page);
46 + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy);
47 + kunmap(page);
48 + put_arg_page(page);
49 + }
50 +
51 + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str)))
52 + panic("`rm -rf /` is detected");
53 + }
54 +
55 would_dump(bprm, bprm->file);
56
57 retval = exec_binprm(bprm);
58 --
59 2.17.1
60
17行目の時点でexecve()の引数はカーネルのメモリに保存されています。ここからが本パッチの変更がはじまります。
検出したいコマンドはrm -rf /であり、かつ、このときの引数の数は3です。これに加えてbprm->argcにはexecve()に渡された引数の数が入っています。よってbprm->argc >= 3という条件のif文によって関係ないコマンド実行を弾いています。べつに>=ではなく==でもよかったのですが、rm -rf / fooとかやっても(このときの引数の数は4)ひどいことになるのには変わりがないのでこうしました。
コマンドライン引数はカーネルメモリ内の所定領域に、各引数をNULL文字('\0')で区切ったデータとして配置されています。たとえばechoコマンドにhelloという文字列を引数として実行した場合は"echo\0hello"というデータになります。コマンド名も引数の一つということに注意してください。rm -rf /の場合は"rm\0-rf\0/"になっているはずです。前述のif文の中身では22行目に「こうあるべき」なデータを置いて、それと実際の引数の値を51行目において比較して、マッチすれば52行目においてカーネルパニックさせています。
カーネルメモリ内からデータをとってくるのが少々やっかいです。これは27~49行目に対応します。必要とするデータはメモリ上の1ないし2ページ(CPUが仮想記憶という機能によってメモリを管理する単位。x86_64アーキテクチャにおいては4KB)にまたがって存在しています。殆どの場合は1ページに収まります。この場合は27行目から37行目だけで終わりです。2ページにまたがる場合は39行目から49行目を実行します。ここではデータが1ページにおさまっている場合についてのみ書きます。
27~37行目はそれぞれ次のような意味を持ちます。
- 27行目: カーネルメモリからもってくるデータのサイズ。データが一ページに収まる場合は9バイト
- 28~32行目: データが入っているページを指すpage構造体と呼ばれるデータを得る、およびそのエラー処理をする。このpage構造体は37行目において解放する
- 33行目: ページ構造体が示すページのアドレスを得る。kmap()によって得たアドレスは36行目のように対応するkunmap()を呼ぶのがお約束
- 34,35行目: 必要なデータをbufにコピー
駆け足で説明しましたがとりあえずフィーリングで読んでみてなんとなくわかればいいと思います。
おわりに
第一回と書きましたが、二回目以降があるかどうかは記事への反響と私のやる気次第です。
自作OSとかLinuxカーネルについて役立った本
はじめに
なんらかの理由によってOSやOSカーネルに興味を持つ人は多々います。しかし、その次のステップとしてどんな本を読めばいいんだろうと思っている人はこれまたいっぱいいます。そこで、長年Linuxカーネルにかかわってきた筆者がこれまでに読んでよかったと思うものについてここの列挙しました。紹介するのは本だけであって、記事は省いています。もう一点、筆者が書いたものは省いています。
OSそのものに興味を持った人は、その後に興味の方向が次のような二つに分かれることが多いと筆者は考えています。
- オレオレOSを作りたい
- 既存のOSを改造したい
この仮説をもとに、それぞれについて筆者がかつて真面目に読んだ本の中から「自作OS」および「Linuxカーネル」というキーワードでよかったものを挙げておきます。Linux以外の既存OSについては語れるほどの知識はないので書いてません。
筆者について
本の良し悪しは人によってさまざまなので、筆者がどういうスキルセット、好みを持った人なのかを最初に書いておきます。わたしにとっての良書はみなさんにとっての悪書かもしれません。
- 3年くらい前まで10年以上Linuxカーネル開発、サポートをしていた
- 最近は枯れているdistributionカーネルのトラブルシューティングが中心。最新のカーネルについてはたまに興味のある最新機能を評価したりパッチ投げたりしてるだけ
- 技術書は要点だけ説明していて後は自分でやってね、という本が好み
- 分厚くて記述の粒度が細かい本は苦手
- 文字より図やグラフを多用した説明を好む
自作OS本
30日でできる! OS自作入門
この界隈で一番有名な本。通称「30日本」。ブート処理を実装して画面を出してその他諸々やって、後は好きなようにしてね!というやつです。この本当に好きなようにした人が多くて本書をきっかけとして多数のオレオレOSが生み出されました。
本の中のかなり早い時期にWindowsのような画面を出して見た目に訴えようとしたり懇切丁寧な書き方にしていたりと、「なんとか最後まで読んでもらおう」という気配りがされていますので、やる気さえあれば挫折率は低いかと。この手の本は「書いてることは合ってるし、これを読み通せばOSを作れるようになるんだろうけど読み通すのが非常につらい」というものが多いので、読んだ当時は非常にびっくりしました。本書を小学生のときに読んでそのままOSオタクになった人たちもいるので小学生でも読めるのかもしれません。
長所はそのまま短所にもなります。いわゆる世間一般でいうOSよりかなり機能が絞り込まれているので、この本を読んだ後は他の本によってさらにステップアップを目指すことになるでしょう。
12ステップで作る組込みOS自作入門
その名の通り組み込みOSを作るための本です。ネット経由で買える安い組み込みボード上に簡単なOSを書いています。作ったときの見た目の派手さは30日本に軍配が上がりますが、こっちのほうが一般にイメージされているOSに近いです。「コンソールに文字出せた!」ということで喜べる人はこっちのほうがいいかもしれません(私は30日本よりもこっちのほうが好きです)。
筆者は本書を見たときにPC上に簡単なOSを実装できる程度の知識はあったものの、それ以外については全く知識が無かったので、「なるほど組み込みボードはPCとこんな風に違うのね」と非常に興味深く読んだと記憶しています。
オペレーティングシステム 第3版
いわゆるタネンバウム本です。5000行くらいでUNIX、Linuxっぽいカーネルを実装しています(「Linuxっぽい」とかいうとタネンバウム先生に怒られそうですが、読者目線であえてこう書いています)。OSとは何であるか、昔はこうであったなどのトリビアも非常に楽しめました。ただしけっこう記述がお堅いのと物理的にデカいのが難点です。
真面目に読みこなすと自作カーネルの上でUnix系OSのコマンドが動かせるようになるので、けっこう感動すると思います。
最後にひとつ。ネット上には「タネンバウム本は古すぎる」という記載が多々ありますが、それらは主に旧版に対する指摘です。三版の内容はけっこうモダンです。
Linuxカーネル
最初に言っておくと私が紹介する本はすべてかなり古いです。なぜなら私がLinuxカーネルの本を積極的に探してたのは数年前までで、その後はLKML(Linux開発の中心となっているメーリングリスト)を追ったり、何かあれば直接ソース見たりしてたので、新しめの本がどうかは知らないからです。ではこれから紹介する本が役立たないかというと決してそうではないと思います。たしかに実装がガラっとかわってしまっているものもあるのですが、変わっていないところも多々あるので、これらは現在のカーネルを理解するのにも非常によい助けになるはずです。
Linux Kernel Development
カーネルとは何か、カーネル開発とは何か、ユーザプログラム開発と何が違うのかをざっと説明した後にLinuxの実装について細かくソースの説明ではなくコアとなる構造体やロジックについて述べています。平易で読みやすくてそれほど分厚くないというのもポイント高いです。
わたしはこの本でLinuxカーネルに入門しました。カーネルとは何かというのを概念的にはざっと知っていたものの具体的にはどんなものかわかっていなかった、という本記事の読者のような状態で読んだところ、十分に理解できたと記憶しています。とてもいい本です。
詳解Linuxカーネル
世間的に「Linuxカーネルといえばこれ」という本。いろんなことを事細かに説明してあるので、概要より詳細を知りたいという人にはいいと思います。まじめに前から順番に読むというよりは「この関数は何をするためのものだろう」と目次を引いて調べる…というように辞書的に使うのがよいかもしれません。
細かいところはどうでもいいという人はソースを一行一行説明しているようなところをさくっと読み飛ばすと実はそんなに読むのに時間はかかりません。
Linuxカーネル2.6解読室
説明の粒度的にはLinux Kernel Developmentと詳解Linuxカーネルの間にあるような本です。個人的にはLinux Kernel Development, Linuxカーネル2.6解読室、詳解Linuxカーネルの順番で読むとよいと思います。
私は駆け出しのカーネルエンジニアのときにずいぶんと本書のお世話になりました。最大の問題は絶版になっているのか新刊が手に入らないことでしょう。中古高い。
おわりに
これまでに述べたものはあくまで数年間この手の本を真面目に読んでいない筆者が良いと思ったものなので、今はもっといいのがあると思います。「わたしはこの本が好きだ!」とかいうのがあればコメント欄に書いていただけると私やこの記事を見た人が喜ぶかもしれません。一つ確実に言えるのは、少なくともLinuxカーネルについては現在(昔もだけど)日本語より英語の情報が圧倒的に多いことです。まじめに取り組みたいなら英語を恐れるなかれ、です。
システムを一時的に停止させるカーネルモジュール
はじめに
システムを一時的に停止させるstop-machineというカーネルモジュールを紹介します。ソースはここにあります。使いかたはREADMEを見てもらえればわかります。
Ubuntu 18.04上でlinuxカーネル4.18.0-18-genericを起動させた状態で動作検証をしました。
現在の実装ではカーネルモジュールをロードしてから5秒だけシステムを停止させます。ソースの中のSTOP_MSECS定数を変更すればミリ秒単位で一時停止させる時間を変更可能です1。ここでいう停止とは次のようなものです。
- あらゆるプロセスが動作できない
- あらゆるデバイスが動けない。正確にいうとデバイスから割り込みが上がってきても停止が解除するまで待たせられる。
- 上記に伴いストレージI/O、ネットワークI/Oが動かないし、ユーザからの操作も一切付けつけない
考えられる用途
このモジュールは、システムが応答しなくなったような状態でソフトウェアがどう振舞うかというテストを簡単にできるので便利です。
例
本当に止まっているかを確認してみましょう。まずはモジュールをロードするのとは別の端末を開いて、1秒ごとに現在時刻を表示するスクリプトを動かします。
$ for ((;;)) ; do sleep 1 ; date -R ; done Sat, 04 May 2019 09:40:27 +0900 Sat, 04 May 2019 09:40:28 +0900 Sat, 04 May 2019 09:40:29 +0900 Sat, 04 May 2019 09:40:30 +0900 Sat, 04 May 2019 09:40:31 +0900 ...
この状態でもとの端末に戻ってモジュールをロードすると、約5秒後にshellのプロンプトが出てきます。
$ sudo insmod stop-machine.ko $ # insmodコマンドを発行してから約5秒後にこのプロンプトが出てくる
一秒ごとに現在時刻を出力していた端末では5秒間時間が飛んだように見えていることがわかります(以下実行例の☆1から☆2の間)。
... Sat, 04 May 2019 09:44:38 +0900 Sat, 04 May 2019 09:44:39 +0900 Sat, 04 May 2019 09:44:40 +0900 Sat, 04 May 2019 09:44:41 +0900 Sat, 04 May 2019 09:44:42 +0900 Sat, 04 May 2019 09:44:43 +0900 Sat, 04 May 2019 09:44:44 +0900 ☆1 Sat, 04 May 2019 09:44:49 +0900 ☆2 Sat, 04 May 2019 09:44:50 +0900 Sat, 04 May 2019 09:44:51 +0900 ...
最後に現在時刻を出していた端末を閉じた上で、モジュールを以下のようにアンロードしておきましょう。
$ sudo rmmod stop-machine $
実装のはなし
このモジュールは、linuxカーネル内のstop_machine()という関数を使っています。この関数は第一引数によってシステム停止中に実行するハンドラを、第二引数によってこのハンドラ実行時に渡される引数を、第三引数によって「どのCPUを停止させるか」を決めます(NULLにすれば全CPU)。stop_machine()関数はカーネル内で他の処理に一切割り込まれたくない処理において使われます。このモジュールにおいてはハンドラの中で1秒だけCPUを使うような無限ループを全CPU上で回しています。
stop_machine関数について興味のあるかたはソース2をごらんください。この記事を書いた後にakachochinさんが大変よい記事を書いてくださったのでまずはこちらを読むといいと思います。
なんでもかんでも「バグ」ってひとくくりにしないで
はじめに
プログラマがソフトウェアを作るとユーザがつきます。ユーザがそのソフトウェアを使っていて何らかの問題が発生すると「このソフトはバグってる、直して!」と言われることがままあります。それに対して「いや、仕様だから」と突っぱねられることがあります。その後お互いの意見が「バグだ!」「いいや仕様だ!」と平行線になってお互いモヤモヤのまま終わるというのはよくある話です。
なぜこういうことが起きるかというと、原因の一つは「問題」イコール「バグ」という短絡的な考え方です。とくにソフトウェアを作ったり使ったりした経験が浅い人がこうなる傾向があると推測しています。このような食い違いは「要件」「仕様」と「実装」という言葉の意味を理解していればある程度解決できます。本書はこれらの用語について実例を挙げて簡単に紹介します。
注意点
- 本記事では要件や仕様を定義することが前提となっていますが、とくにユーザと開発者が同じような場合にはこれらが明確でないことがままあります。OSSにおけるこのあたりの感覚についてはこの記事が非常に参考になります。興味のあるかたはごらんください
- 原因がわかったときにその責任がどこにあるかについて。たとえば原因がソフトウェアの誤りであることがわかっても、たとえばGPLのように「無保証」と銘打っているライセンスを採用しているソフトウェアについては「ここバグってるからソフトウェアを直して」とユーザが言っても開発者には直す責任はありません(運が良ければ直してくれることもあります)。この場合は自分で修正を作って開発者に提供して直してもらうなどの対処が考えられます。このあたりは本記事のスコープから外れますのでこれ以上は述べません。今後「開発者に責任がある」と書いている場合は、無保証のソフトウェアについては状況が違うと考えてください。
- 本記事に書いてあるようなことは百も承知で、自分あるいは自分の所属する組織に有利になるようにゴネる人もいますが、そういうケースはここでは扱いません。同じく、責任が誰にあるかは明確であってもユーザと開発者の力関係によって誰に責任があるのかが政治的に決まる、場合によっては両者の意見の相違によって裁判沙汰になることもありますが、それについてもここでは扱いません。
要件
ソフトウェアを作る際には、最初に「いったどういうソフトウェアを作りたいのか」という要件を定義します。ここでは次のような要件があるとします。
- ある組織に複数の人が属している
- 個々人について名前と年齢という情報が並べられた表を管理したい
- 年齢をキーとして組織に属する人すべての情報を昇順に表示したい
この要件定義はユーザ(自分自身かもしれません)の思いを反映しているものとします1。
仕様
仕様とはソフトウェアのあるべき姿です。ここでは個々人の情報を以下のstruct personという構造体を使って扱うものとします。
struct person { char *name; int age; }
ここでageは必ず0以上の数値にしなければならないとします。
ここからはstruct personという構造体の配列をソートするsort()という関数の仕様を次のように定義したとします。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて昇順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のaはa[0]->age <= a[1]->age <= ... <= a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
仕様の誤り
ここでsort()関数の仕様が前節において述べたものではなく次のようなものだったとします。もとの仕様と違うところは太字で書いています。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて降順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のaはa[0]->age >= a[1]->age >= ... >= a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上。lenが0未満の場合の動作は未定義- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
要件によるとsort()関数は配列aを昇順にソートすべきでしたが、ここでは降順にソートしてしまっています。このように要件に沿っていない場合は開発者が作った仕様が誤っているという問題が発生したといえます。誰に責任があるかは契約次第なのですが、ユーザが仕様にOKを出して全責任を負う、という契約であればユーザの責任ですし、開発者が仕様を自由に決めてよくて、かつ、開発者が責任を負うという契約の場合は開発者の責任となります。
仕様の誤りには他にも次のようなものが考えられます。
- インターフェースは
int sort(struct *person[] a, int len) - 配列
aをageフィールドに基づいて降順にソートする。ソートされた新しい配列を作るのではなくaの中身をそのままソートする。呼び出しが成功した場合は呼び出し後のa[]はa[0]->age < a[1]->age < ... < a[len - 1]->ageとなる - 引数の意味
a: ソート対象の配列len:aの長さ。1以上。lenが0未満の場合の動作は未定義- 戻り値
0: 成功1: 失敗。ageが0未満のときやlenが1未満のとき
こちらは個々人の年齢が同じ場合に仕様を満たせないため、これも仕様が誤っていると言えます。
実装
ではsort()関数の実装について考えます。ここでいう実装とはsort()関数を仕様に定められた通りに動くようにコード化することです。仕様を満たしさえすればどういう実装にしてもかまいません。なお、ここでは実装のコードそのものは重要ではないので考えません。
実装の誤り
sort()関数の実装が、a[]を降順にソートしてしまうものだった場合はどう考えればいいでしょうか。これは実装が仕様を満たしていないので、開発者による実装の誤りが発生した問題と言えます。責任の所在については、たとえばユーザが仕様にOKを出して全責任を負う、という契約であればユーザの責任ですし、開発者が仕様を自由に決めてよくて、かつ、開発者が責任を負うという契約の場合は開発者の責任となります。
使用方法の誤り
sort()関数の仕様も実装も正しいとします。ではこれで問題が発生しないかというとそんなことはありません。たとえばユーザがデータ入力を間違えており、a[]の中にageが-10の要素があったとします。この場合、sort()関数はエラーを示す1を返します。ここでユーザが「なぜソートされていないんだ、これは問題だ!バグだ!」ということはよくあるのですが、これはsort()関数自体は仕様通りに1を返しているだけなのでユーザが使用方法を誤っているといえます。
実装依存のふるまい
sort()関数の実装に使われるソートアルゴリズムには安定ソートと不安定ソートという二種類のものがあります。これらの意味については本記事のスコープを外れるのでwikipediaの記事などをご覧ください。sort()関数の仕様を見ると、この関数が安定ソートなのかどうかということは定められていません。このような場合に実装においてどちらの種類のアルゴリズムにするかは開発者にゆだねられています。
ここでユーザが「ソートといえば安定ソートだろ」という想定でこのソフトウエアを使って思い通りにならなかった場合に「これは問題だ!バグだ!」ということがありますが、これについては安定ソートか否かは仕様によって未定義なので責任は通常ユーザにあります。
バージョンアップと実装依存
たまたまsort()関数が安定ソートであり、かつ、ソフトウェアのバージョンアップに伴いsort()関数の実装が変わって不安定ソートにする場合はどのように扱えばよいでしょうか。これについては考え方が色々ありますが、原理原則からいうと未定義の動作がどうなろうとこれは問題ありません。ただし特別な理由がない限りこういうことは避けるほうがよいでしょう。文化によってはこの手の変更が決して許されないこともあります。
おわりに
ここまでみてくださったかたがたに感謝いたします。これを読み切ったかたの多くは何らかの形で本記事冒頭で述べたような状況に遭遇したことがあるのではないかと思います。それが作る側であったとしても使う側であったとしても、言葉の定義があやふやなことによる不幸な話の食い違いがこの記事によって多少なりとも減ることを祈ります。
-
とくにユーザと開発者が違う人の場合に要件定義がそもそも間違っていることも多々ありますが、それについては割愛します↩
APIとかABIとかシステムコールとか
はじめに
本記事はLinux環境における次のようなことをざっくり理解するための記事です。
- Application Programming Interface(API)って何?
- Application Binary Interface(ABI)って何?
- システムコールとAPIとABIの関係って?
- それぞれ何がどう違うの?
この手の情報はググればwikipediaやらにいろいろ情報が載ってるんですが、初心者が理解するには細かいことまで書かれすぎていて、かつ、それぞれの関係がわかりにくいです。なので、用語を逐一解説するのではなく、ありがちな質問のQAという形をとりました。人によって用語の意味の揺らぎがあったりするんですが、私の解釈ということで。あからさまに間違っていたら指摘していただけると嬉しいです。
これを書こうと思ったきっかけは、以前こんなtweetを見かけたことです。それから「そういえば最近使われる言語はコードやデータがどういうバイナリに落ちるかが見えないものが多いので、この手のことはあんまり知られてないなかなー、知ってると楽しいんだけどなー」と思ったことです。
APIって何?
APIは、ソースコードレベルで関数(OOPLのメソッドも含む)やデータ(OOPLのクラスも含む)の仕様を規定したものです。それらの関数やデータがどのようなバイナリデータとして表現されるかは気にしません。
ここ最近ではプログラミング言語のAPIだけではなく、webサービスにリクエストを出すときにどういうURLにどういうリクエストを出すとどういうレスポンスが得られるかを規定したWeb APIのほうがなじみがあるかもしれません。
ソースをもとにAPIを説明します。以下のようなCソースを書くとします。
int plus(int x, int y) { return x + y; } int main(void) { int a = 1; int b = 2; .. plus(a, b): .. }
このときplus()のAPIは「第一引数にint型の値、第二引数にint型の値を渡すと、それを足し合わせたint型の値を返す」です。繰り返しになりますが、CPUのアーキテクチャやCコンパイラの実装に依存するエンディアンやintのバイト数などは気にしないです。
ABIって何?
ABIはバイナリレベルで「関数(OOPLのメソッドも含む)やデータ(OOPLのクラスも含む)の仕様を規定したものです。エンディアンとかデータのサイズも気にします。もっというと前節に記載したソースでいうとplus()呼び出し時にアセンブリ言語レベルで各引数をどういうアドレスに配置してからどういう命令を呼び出すかという呼び出し規約も気にします。
呼び出し規約については(とくにx86_64アーキテクチャの)アセンブリ言語を若干でも知っている人は以下の情報を見るとなんとなくわかるかと思います。
- wikipediaの"呼び出し規約"のページ
- System V Application Binary Interfaceの"3.2 Function Calling Sequence"
ABIはたとえば次のようなときに姿を現します
- バイナリ形式ライブラリの関数を別のアプリないしライブラリから呼び出すとき
- プログラムから使うプロトコルのバイトオーダーが指定されているとき
「APIを叩く」ってどういう意味?
「APIに従って関数を呼ぶ」ことを意味するスラングです。あまり深く考えなくてもいいです。
POSIX APIとシステムコール呼び出しの違い
POSIX APIはPOSIXと呼ばれる規格において定義されている、主にUNIX系のOS間で移植性を高めるために作られたC言語関数のAPIセットです。linuxはPOSIXに準拠していませんが、POSIXに定義されているAPIはおおよそ備えています。Ubuntuにおいてはmanpages-posixをインストールしてman 3 readというコマンドを実行するとPOSIX APIとしてのread()の仕様が読めます。
システムコールはプログラムからハードウェアを操作したいなどの要求をカーネルに依頼する方法です。こちらはAPI(たとえばman 2 readとするとread()システムコールの定義を調べられる)と共にABIも決まっています。
- System V Application Binary InterfaceのA.2.1 Calling Conventions
通常はレジスタないしメモリ上の所定の位置に引数の値を書き込んでから特殊なアセンブリ命令を呼び出す、という方法で呼びます1。
POSIX APIのうちのカーネルを呼び出す必要がある関数についてはABIに基づいてシステムコールを呼び出す必要がありますが、関数名とシステムコールの名前が一対一対応している必要はありません。たとえばglibcにおいてはfork()関数を呼び出すと内部的にはclone()システムコールを呼び出します。POSIX APIとしてfork()の仕様に書いてあることが実現できたら、内部的にどのシステムコールを使うかという実装詳細はなんでもいいのです。
システムコールはC言語からしか直接呼び出せないの?
「直接」の定義にもよりますが、実は私の意見は「アセンブリ言語以外のC言語を含むあらゆる言語は直接システムコールを呼び出せない」です。
C言語においてもシステムコールを呼び出すときは内部的にはアセンブリ言語を使っています。例えばglibcにおいてはプログラマがglibcのread()を呼び出すと、この関数の中ではインラインアセンブラという機能を使ってアセンブリ言語によってシステムコールを呼び出しています。あるいはアセンブリ言語で書かれたシステムコールを呼び出す関数を含んだライブラリを呼び出すという手もあります。こういう方法を「直接」呼び出していると思うかどうかは人によるでしょうが、上述の通りわたしはそう思いません。
C言語以外の「直接システムコールを呼び出せる」と言われている言語においても最終的には上記と似たような方法を使っています。
あるプログラミング言語から他のプログラミング言語の関数はどうやって呼び出すの?
呼び出し元の言語と呼び出し先の言語の間を繋ぐなんらかの仕組みを使います。たとえばCとpythonをつなぐ方法は次の通り。
なんで低レイヤプログラミングだとCがよく使われるの?
ここは人によって様々でしょうが私が思う理由は次の通り。
- プログラマがメモリをほぼ剥き出しの形で扱える(裏を返せば「扱わなくてはいけない」)2
- 異なるコンパイラ、異なるバージョン間でのABI互換性が高い
- 言語仕様が小さいため、処理系が比較的作りやすく、かつ、メモリ消費量も小さい
- 低レベルのAPI規格はPOSIX APIのようにC言語用のものが多い
- ある言語から別言語を呼び出すためにCを中継することが多い(前節を参照)
- 十分に枯れており、周辺ツールがたくさんある
おわりに
気が向けば次のようなことを扱った続編を書くかもしれません。
- 互換性とは何か
- ライブラリのバージョニング
- ELF symbol versioning
linuxカーネル内部インターフェースの変更例
はじめに
Linuxカーネル(以下カーネルと表記)の外部ユーザ空間とのインターフェースはシステムコールが増えることはあっても既存のものが変更されることはほとんどなく、極力互換性が保たれるようになっています。しかしカーネル内部のインターフェースはめまぐるしく変わります1。本記事ではその一例として、カーネル内で一定時間後に所定の処理を呼び出すタイマーという機能のインターフェースが変更された話、およびその影響について紹介いたします。
何もしてないのにビルドできなくなった
筆者が昔々、およそ8年前書いた以下のカーネルモジュールのコードを本日カーネルv4.18のモジュールとしてビルドすると★★★と書いた行でエラーが出ました。
#include <linux/module.h>
#include <linux/timer.h>
MODULE_LICENSE("GPL v2");
MODULE_AUTHOR("Satoru Takeuchi <satoru.takeuchi@gmail.com>");
MODULE_DESCRIPTION("timer kernel module: oneshot timer");
struct timer_list mytimer;
#define MYTIMER_TIMEOUT_SECS 10
static void mytimer_fn(unsigned long arg)
{
printk(KERN_ALERT "10 secs passed.\n");
}
static int mymodule_init(void)
{
init_timer(&mytimer); ★★★
mytimer.expires = jiffies + MYTIMER_TIMEOUT_SECS*HZ;
mytimer.data = 0;
mytimer.function = mytimer_fn;
add_timer(&mytimer);
return 0;
}
static void mymodule_exit(void)
{
del_timer(&mytimer);
}
module_init(mymodule_init);
module_exit(mymodule_exit);
エラー内容は「init_timer()という関数は存在しない」というものでした。この関数はタイマーを初期化するためのものです。上記コードを書いた時点では古いカーネルについてビルドは成功していたことから、この古いカーネルからv4.18までのある時点で当該関数が削除されたということが言えます。では、どういう理由でどのような流れでこうなったかをこれから紐解いていきましょう。
init_timer()が消えた理由
結論からいいますと、カーネル内のinit_time()を使っていた箇所はすべて新しいtimer_setup()という関数を使うように置き換えられています。その上でカーネル内部でユーザがいなくなったinit_timer()は削除されました。
事の発端はinit_timer()のインターフェイスにセキュリティホールを生みやすいなどの色々問題があったことからtimer_setup()を追加するパッチが提案されて、それが公式カーネルにマージされたことです。
init_timer()とtimer_setup()の違いはざっくりいうと次の通りです。
- タイマーが時間切れになったときに呼び出されるコールバック関数を、タイマーの初期化関数(timer_setup())を呼ぶときに引数として設定するようになった
- コールバック関数の引数がタイマーを表すstruct timer_list型のデータのdataフィールドではなく当該データそのものへのポインタになった
コードを使って違いを説明します。タイマーを登録してから10秒後にmytimer_fn()を呼び出したいときにはinit_timer()は次のように使います。
...
struct timer_list mytimer;
...
{
...
init_timer(&mytimer);
mytimer.expires = jiffies + 10*HZ; // 10秒後にタイマーを起動させる。jiffiesは現在時刻を指す
mytimer.data = 0; // 下記関数が呼び出されたときの引数として渡される値
mytimer.function = mytimer_fn; // コールバック関数
add_timer(&mytimer);
...
}
...
static void mytimer_fn(unsigned long arg)
{
...
}
これに対してtimer_setup()は次のように使います。
...
struct timer_list mytimer;
...
{
...
timer_setup(&mytimer, mytimer_fn, 0); // 第三引数にはフラグを設定。ここでは説明を省略
mytimer->expires = jiffies + 10*HZ;
add_timer(&my_timer);
...
}
...
static void mytimer_fn(struct timer_list *t) // タイマーが切れたときにはtはmy_timerを指す
{
...
}
このようなときにlinuxは過去のソフトウェアに多かった「今後はinit_timer()ではなくtimer_setup()を使ってね、すでにinit_timer()を使っているコードはそのまま動くよ」というやりかたではなく、「既存のinit_timer()呼び出しを全てtimer_setup()に全部置き換えた上でinit_time()を丸ごと削除するぜ」という大規模なリファクタリングをすることがよくあります。今回のタイマーの初期化についてはリファクタリングをする方向に舵が切られたというわけです。
移行は一度にやると間違いが発生したときのトラブルシューティングが大変なので、注意深く段階的に行われました。移行後は前述のようにinit_timer()は新たなユーザーが現れないように削除されました。
細かい置換の過程に興味のあるかたはinclude/linux/timer.hやkernel/time/timer.cをgit blameで調べるなどして深掘りしてみてください。みなさんが今後ご自身のコードをリファクタリングするときの参考になるかと思います。
移行による影響
移行による影響度はみなさんに関係のあるカーネル関係のコードが公式のカーネルソースにマージされているかどうかによって大きく異なります。マージされている場合は変更を施した人か、あるいはサブシステムメンテナなどの、そのコードに責任のある人が関連コードを変更します。それに対してマージされていない独自パッチや独自モジュールなどは自分で全部修正しなければいけません。後者の典型例は本記事の最初に述べた筆者独自のモジュールです。
カーネル関連コードを書く場合は公式カーネルにマージするほうが好ましい(ことが多い)理由の一つがこのようなインターフェースの変更などに追従するコストが減ることです。筆者のコードの場合は節題にした「何もしてないのにビルドできなくなった」ではなく、「何もしなかったからビルドできなくなった」というわけです。
おわりに
本記事ではlinuxのカーネルの外部インターフェースは保たれるが内部インタフェースは保たれないということ、および、インターフェース変更による影響を最小化するにはコードを公式カーネルにマージしておく必要があることを述べました。今後みなさまがカーネルおよびカーネルモジュールの開発をするときの助けになれば幸いです。
Socionext SC0FQAA-BはNUMAか否か
はじめに
本記事はLinuxのプロセススケジューラから見たSocionext SC2A11の続きです。Socionext SC0FQAA-B(以下「本マシン」と記載)は24コアのSC2A11を1つ搭載しています。このマシンがNUMAかどうか、言い方を変えるとSC2A11内の各コアがすべてのメモリに等速でアクセス可能かどうかを調査しました。
結論
本マシンはNUMAではないと推測しました。
linuxからの情報取得
まず、arm64はNUMA構成をサポートしています。LinuxのDevice Treeのドキュメントによると、Device TreeでNUMAを表現するには、各デバイスの定義内のnuma-node-idというトークンによってデバイスが所属するNUMA IDを定義します。
しかし、SC0FQAA-BのDevice Treeにはこのトークンは見つかりませんでした。
$ find /sys/firmware/devicetree -name numa-node-id $
ここで終わりかというとそうではなくて、ハードがNUMAとして見せていないにも関わらず、実測してみると実質NUMAだと明らかになる、というのは珍しい話ではありません。
実験
使用するプログラム
データ採取には次のような仕様のプログラムを使います。
- コア0上でL3キャッシュを超えるサイズのバッファ(ここでは16MB)を取得する
- 以下を24コアのすべてにおいて繰り返す。コア番号をnとする
- 2-1. プロセスをコアnに移動させる
- 2-2. 上記バッファに所定の回数アクセスすることによってメモリアクセス速度を計測
処理1において取得したメモリはプログラムの実行中に物理アドレスが移動することはないため1、処理2-1においてコアを移動した場合にバッファへアクセス速度が変化すれば、おそらく本マシンはNUMAだろう、というわけです。
これを実装したのが次のnuma.cプログラムです。
#define _GNU_SOURCE
#include <sched.h>
#include <unistd.h>
#include <sys/mman.h>
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
#define CACHE_LINE_SIZE 64
#define NLOOP (64*1024*1024)
#define BUFFER_SIZE (16*1024*1024)
#define NCORE 24
#define NSECS_PER_SEC 1000000000UL
static inline long diff_nsec(struct timespec before, struct timespec after)
{
return ((after.tv_sec * NSECS_PER_SEC + after.tv_nsec)
- (before.tv_sec * NSECS_PER_SEC + before.tv_nsec));
}
static void setcpu(int n)
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(n, &set);
if (sched_setaffinity(getpid(), sizeof(cpu_set_t), &set) == -1)
err(EXIT_FAILURE, "sched_setaffinity() failed");
}
int main(int argc, char *argv[])
{
char *progname;
progname = argv[0];
register int size = BUFFER_SIZE;
setcpu(0);
char *buffer;
buffer = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (buffer == (void *) -1)
err(EXIT_FAILURE, "mmap() failed");
int i;
for (i = 0; i < NCORE; i++) {
setcpu(i);
struct timespec before, after;
clock_gettime(CLOCK_MONOTONIC, &before);
int j;
for (j = 0; j < NLOOP / (size / CACHE_LINE_SIZE); j++) {
long k;
for (k = 0; k < size; k += CACHE_LINE_SIZE)
buffer[k] = 0;
}
clock_gettime(CLOCK_MONOTONIC, &after);
printf("%d\t%f\n", i, (double)diff_nsec(before, after) / NLOOP);
}
if (munmap(buffer, size) == -1)
err(EXIT_FAILURE, "munmap() failed");
exit(EXIT_SUCCESS);
}
結果
結果は次の通りです。第一フィールドがデータを採取したコア、第二フィールドがメモリアクセス処理に所要時間です。
0 37.300696 1 37.511301 2 37.320645 3 37.479546 4 37.280271 5 37.298240 6 37.207461 7 37.285339 8 36.824337 9 36.862199 10 36.926653 11 36.867224 12 37.064979 13 37.011814 14 37.041438 15 37.074635 16 37.414566 17 37.373740 18 37.375946 19 37.423050 20 37.292513 21 37.323017 22 37.154486 23 37.190995
次に示すのは、コア0上でバッファにアクセスする測定を24回繰り返した結果です。
36.993787 36.986646 37.254620 37.231557 37.587849 37.582042 37.450369 37.387533 37.487312 37.452216 37.501526 37.556768 37.139728 37.283043 37.169193 37.389888 37.746065 37.841875 37.559928 37.581090 37.769728 37.680080 37.567870 37.194819
いずれも37秒前後1秒程度の差に収まっているため、アクセス速度にあまり違いはないといっていいでしょう。つまり、ある物理メモリ(numa.cにおいて取得したバッファ)には24個いずれのコアからもおおよそ等速でアクセスできたということです。numa.cの処理1においてバッファを採取する際のコアを1-23に変えても結果は同じでした。これによって本マシンは恐らくNUMAではなかろうと推測しました。
-
メモリが断片化してきた場合はコンパクションという機能によって物理メモリが移動することがありますが、今回はほとんどのメモリが空いている状態なのでその心配はありません。↩