Linuxカーネルソースの統計情報
はじめに
本記事はlinuxカーネルのソース分析によって、このソフトウェアの様々な特徴を可視化します。ソースの総行数といったありがちなものから、1つのバージョン内のrelease candidate(rc)ごとのパッチ数の推移やサブシステムごとのデータなども出しています。
linuxには、v2.6.x, v3.x, v4.xで表す、Linuxのオリジナル開発者であるLinus Torvalds氏がリリースするmainlineカーネル(通常、単にLinuxと言えばmainlineカーネルを指す)があります。このうち、データ採取した範囲はgitで追える範囲のv2.6.12〜v4.10までです。ものによってはv4.0〜v4.10までの範囲です。
全体の傾向
総行数

行数は*.[chS]というパターンにマッチする行の数を使いました。v2.6.12では600万行そこそこ(それでも凄いのですが)だったのが、12年弱後に出た執筆時点では最新のv4.10では約4倍の2100万行弱まで増加しています。行数はおおよそ単調増加していますが、唯一v3.17だけ4万行程度減少していました(理由は後日調査するかも)。増加速度が衰える気配は見えておらず、未だ活発なプロジェクトであることがわかります。
パッチ数

v2.6.24あたりまでは増加傾向にありますが、その後はバージョンごとに一万から一万五千パッチあたりをうろうろしています。やや増加傾向にあると言えるかもしれません。行数ではなくパッチ数という観点で見ても開発は活発といえます。
増加行数

ばらつきはありますが、平均すると、リリース毎におよそ25万行増加しています。linuxカーネルは9〜10週程度に一度新バージョンをリリースしますので(詳細は後述)、一週間ごとに2万〜3万行、一日ごとに3千〜4千行増加しています。linuxの開発には、いかに莫大なリソースが投入されているかがわかります。
ただし、これはあくまでリリース版に入ったコードだけの話なので、実際には
- 上記の通り、単に行の追加だけではなく削除もしている
- マージされなかったコードが星の数ほどある
などの理由によって、このデータに現れないものも含めた投入リソースはさらに多いです。
パッチごとの増加行数

時を経るに従って増減するわけではなく、バージョンごとにかなりばらばらです。平均すると1パッチごとに20行程度増加しているようですが、このデータだけでは平均値を使うのがそもそも適切かどうか怪しいところです。
rcごとのパッチ数から見るlinuxのリリースサイクル
mainlineカーネルのデータを見るとパッチ数はそれなりに安定していましたが、さらに粒度を細かく見ると、どうなるでしょうか。
linuxは新たなmainlineカーネルをリリースするごとに、その後二週間後に次のmainlineカーネルのrc1がリリースされます。その後一週間ごとにrc2, rc3...とバージョンを重ねることによって安定化させてゆき、rc7の一週間後に次のmainlineカーネルをリリースします。たまにLinus氏の判断により、rc7から一週間後でも安定していないとみなされた場合はrc8が出ることがあります1。
以下はrcリリースごとに見たパッチ数の推移です。

1つのバージョンのリリースまでの流れを追うと、rc1でほとんどのパッチが適用されて、その後はそれに比べればはるかに少ない数のパッチしかマージされないことがわかります。それもそのはず、rc1では新機能パッチに加えてあらゆる修正パッチが取り込まれますが、、rc2以降は基本的にはバグフィックスパッチしか入らないからです。
rc1のパッチ数が多すぎるので、縦軸のスケールを変えて、rc2以降に注目したグラフを見てみましょう。

時間の経過に伴い、マージされるパッチの数が減っていっていることがわかります。これは、次版のリリースが近づくほど重要なパッチしかマージしなくなってゆくという開発方針によるものです。
サブシステムごとの情報
これまでにカーネルの総行数について分析してきました。では、カーネルにある様々なサブシステムのうち、どのサブシステムの行数が多いのか、どのサブシステムに対するパッチが多いのかを見てみましょう。ここはソースのトップディレクトリのうち、
- カーネルに関係ないユーザ空間のもの
- ヘッダファイル用(include/)
- ドキュメント(Documentation/)
などを除いた以下のディレクトリをサブシステムとしてデータを採取しました。
| サブシステム名(ディレクトリ名) | 役割 |
|---|---|
| arch | 各CPUアーキテクチャ固有部分 |
| block | ブロックデバイス層 |
| crypto | 暗号化 |
| drivers | ドライバ。キャラクタデバイス、ブロックデバイス、NICなど |
| fs | ファイルシステム。ext4, XFS, Btrfs, nfsなど |
| init | 初期化 |
| ipc | System V IPC |
| kernel | コア部分。プロセススケジューラ、割り込み、タイマー、シグナル制御など |
| lib | 他のサブシステムから使うライブラリ |
| mm | メモリ管理 |
| net | ネットワーク。IPv{4,6}など |
| security | セキュリティ。SELinuxなど |
| sound | サウンド |
| virt | 仮想化。KVMなど |
どのサブシステムの行数が多いか

一見してドライバ(drivers/)のコードが圧倒的に多いことがわかります。その後にアーキテクチャ依存コード(arch/)、第三勢力のファイルシステム(fs/)、サウンド(sound/)、ネットワーク(net/)などが追いかけます。コア部分(kernel/)やメモリ管理(mm/)は実は全体から見ると大した規模ではないというのが面白いところです。
どのサブシステムの増加行数が多いか

ドライバが圧倒的多数を占めており、それに比べるとその他のサブシステムの増加量はほとんど誤差範囲です。linuxのコード量が前述の通り年々凄まじい速度で増加しているのは事実だとしても、その増加量のうちのほとんどはドライバのコードだということがわかります。
ドライバを除いた場合についても見てみましょう。

行数の場合の二位であったアーキテクチャ依存コード(arch/)、第三勢力であったファイルシステム(fs/)、サウンド(sound/)、ネットワーク(net/)の変更量が多いことがわかります。ただし、どのバージョンでどのサブシステムが主に変更されるかについては、とくに規則性は無いようです。
v4.1においてアーキテクチャ依存コードが大幅に減少している理由は不明です。v4.3においてファイルシステムの行数が大量に減少しているのは、ext3のコードが全て削除されたことが主な原因です(ext3が非サポートになったわけではなく、ext3をマウントするとext4のコードで操作するようになりました)。
ドライバのコード
ドライバの種類別のコード量
さきほどlinuxのコードの大部分はドライバのコードだと書きました。では、どのような種類のドライバが多いのかを円グラフにまとめました。v4.10におけるdrivers/以下のディレクトリのうち、ソース行数の多かった上位10のディレクトリと、その他のディレクトリの行数を合計した値を表示しています。

ネットワーク(net/)、GPU(gpu/)、カメラやビデオ、TVなどのマルチメディア(media/)あたりのコードが多いことがわかります。ネットワークドライバについては、ネットワークプロトコル(トップディレクトリの下のnet/ディレクトリ)のコードも多かったことを考えると、linuxのソースはネットワーク関連のコードの割合が高いと言えます。その一方、ブロックデバイスやキャラクタデバイスなどは上位10個に入らない程度のコード量しか無いことがわかります。
新規デバイスをサポートするためのコードと既存ドライバを変更するコード

ドライバに関するソースの増分のうち、ほとんどが新規ドライバ用のコードであり、既存ドライバの変更分はそれに比べると遥かに少ないことがわかります。上述の通り、全体に対する変更量のほとんどがドライバのものであることを考えると、Linuxのソースの増分のうち、かなりの割合が新規デバイスサポート用のコードであるということが言えます。
stableカーネル
linuxにはmainlineカーネルに加えて、あるmainlineカーネルがリリースされてから次のmainlineカーネルがリリースされるまで、重大なバグ修正パッチだけを適用するstableカーネルが不定期にリリースされます。stableカーネルのバージョン番号はv2.6.x.y, v3.x.y, およびv4.x.yです。
各stableカーネルの最新のバージョン番号
あるmainlineカーネルに対する最新のstableカーネルのバージョン(上述のバージョン名のルールにおけるyの部分)を次に示します。

ほとんどの場合、stableカーネルのリリースは数回ないし十数回程度です。しかし、一部のものは、それより明らかに多くリリースされています。これはlongtermカーネルと呼ばれるもので、特定のstableカーネルを長くサポートしたいという人が、その人が定める期限(EOL)まで次版をリリースし続けるというものです。
stableカーネルをリリースするのは、通常はlinuxカーネル開発の大物であるGreg KH氏ですが、別の人がリリースすることもあります。最初はGreg氏がリリースを担当するものの、後になって別の人が引き継ぐこともあります。Grep氏以外にstableバージョンをリリースするのは、ディストリビュータ関連の人が多いです。
stableカーネルのサポート期限
あるmainlineカーネルがリリースされてから、それに対応する最新のstableカーネルがリリースされるまでの日数を次のグラフに示します。

ほとんどは3ヶ月未満(次のmainlineカーネルがリリースされるまでの日数にほぼ一致)でリリースが止まりますが、longtermのものについてはそれより長いです。場合によっては複数年にわたることもあることがわかります。
linuxのバージョンについて説明しているページの"Longterm"の項に記載されているバージョンについては、今後もリリースが続くことに注意してください。
stableバージョンのパッチごとの追加行数

これは明らかに通常バージョンのものより少ないです。1パッチあたり高々平均5行程度の増加に留まっています。これは、stableバージョンに取り込まれるパッチは重大バグの修正であるというだけでは不十分で、ある程度修正量が小さいもののみが取り込まれるというルールに由来しています。
おわりに
本書で統計情報に使ったソースはgithub上に置いています。
Linuxカーネルで学ぶC言語のマクロ
はじめに
本記事は電子書籍版もあります。
linuxカーネルはC言語のマクロを駆使して書かれています。それらのうち、凝ったマクロになじみの無い人には初見では意図がわからない&わかってみれば面白いであろうものをいくつか紹介いたします。対象読者は、C言語のユーザだけれども、マクロは定数定義くらいにしか使わないというライトなマクロユーザです。
マクロを使用する場所に依存するエラーを防ぐ
次のマクロは、二つの引き数の値を置換するだけの単純なものです。
#define swap(a, b) \
do { typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; } while (0)
注目すべきはマクロの定義全体を囲んでいるdo { ... } while (0)という表記です。初見の人には何のことかわからないと思います。考えられる最も単純な定義から遡って、なぜこのような定義にするとよいのかを見てみましょう。
このマクロのdo {} while文のブロックを外したバージョンのマクロを使ってみましょう。
#include <stdio.h>
#define swap(a, b) \
typeof(a) __tmp = (a); (a) = (b); (b) = __tmp;
int main(void)
{
int a = 0, b = 1;
swap(a, b);
printf("%d %d\n", a, b);
return 0;
}
実行例を示します。
$ make swap cc swap.c -o swap $ ./swap 1 0 $
ちゃんと動いているように見えます。しかし、これが次のような使い方だといかがでしょうか。
#include <stdio.h>
#define swap(a, b) \
typeof(a) __tmp = (a); (a) = (b); (b) = __tmp;
int main(void)
{
int a = 0, b = 1;
if (0)
swap(a, b);
printf("%d %d\n", a, b);
return 0;
}
コンパイルします。
$ make swap2
cc swap2.c -o swap2
swap2.c: In function 'main':
swap2.c:4:9: error: expected expression before 'typeof'
typeof(a) __tmp = (a); (a) = (b); (b) = __tmp;
^
swap2.c:10:3: note: in expansion of macro 'swap'
swap(a, b);
^~~~
swap2.c:4:49: error: '__tmp' undeclared (first use in this function)
typeof(a) __tmp = (a); (a) = (b); (b) = __tmp;
...
make: *** [swap2] Error 1
$
期待値はif文の中のswap()マクロは実行せずに端末上に"0 1¥n"という出力をする、というものですが、実際は山ほどエラーが出てコンパイルが失敗しました。ソースをコンパイルせずにプリプロセッサだけをかけて原因を探ってみましょう。
$ cc -E swap2.c
...
int main(void)
{
int a = 0, b = 1;
if (0)
typeof(a) __tmp = (a); (a) = (b); (b) = __tmp;;
printf("%d %d\n", a, b);
return 0;
}
$
一見正しいように見えますが、制御構造を意識して整形してみると、おかしい点がわかってきます。
int main(void)
{
int a = 0, b = 1;
if (0)
typeof(a) __tmp = (a);
(a) = (b);
(b) = __tmp;;
printf("%d %d\n", a, b);
return 0;
}
swap()マクロ内の3つの命令のうち、一行目の一時変数__tmpを宣言している行はif文の中にありますが、それ以外の2命令はif文の外に出てしまっています。これではまともに動くはずがありません。さらに、if文の中に変数宣言のみを1行置くことは許されないので、上記コンパイルログの一行目のようなエラーが出ています。
では次のようにマクロ定義を単にブロック("{}")で囲めばいいのではないか、というかたもいらっしゃるかと思うので、試してみます。
#include <stdio.h>
#define swap(a, b) \
{ typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; }
int main(void)
{
int a = 0, b = 1;
if (0)
swap(a, b);
printf("%d %d\n", a, b);
return 0;
}
$ make swap3 cc swap3.c -o swap3 $ ./swap3 0 1 $
こちらはうまくいきました。しかしこれは次のようなケースではうまくいきません。
#include <stdio.h>
#define swap(a, b) \
{ typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; }
int main(void)
{
int a = 0, b = 1;
if (0)
swap(a, b);
else
printf("Always print this message¥n");
printf("%d %d\n", a, b);
return 0;
}
$ make swap4 cc swap4.c -o swap4 swap4.c: In function 'main': swap4.c:11:2: error: 'else' without a previous 'if' else ^~~~ <builtin>: recipe for target 'swap4' failed make: *** [swap4] Error 1 $
期待値は"Always print this message¥n"の後に"0 1¥n"が出力される、なのですが、謎のコンパイルエラーが発生しました。これについてもプリプロセッサによる処理後のソースを見てみましょう。
$ cc -E swap4.c
...
# 6 "swap4.c"
int main(void)
{
int a = 0, b = 1;
if (0)
{ typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; };
else
printf("Always print this message¥n");
printf("%d %d\n", a, b);
return 0;
}
さきほどと同様に、制御構造を意識してソースを整形します。
int main(void)
{
int a = 0, b = 1;
if (0)
{ typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; }; # ... (1)
else
printf("Always print this message");
printf("%d %d\n", a, b);
return 0;
}
ややわかりにくいのですが、ソース内の(1)のところでCの構文上if文は完結しています。したがって、それに続くelse節はコンパイラから見るとif文無しに突然出てきたように見えるため、エラーが出ていたのでした。
この場合はswap(a,b);の末尾のセミコロンを省けばうまく動作します。しかしこれは明らかに直感的ではないので、このような使い方はできれば避けたいです。上記の命令列を単なるブロックではなく do {} while (0)で囲めば、それが可能になります。コード例は出しませんが、この場合は上記すべての場合についてうまく動作します。
上記のような「うまくいかないケース」を全て知らないと、なかなかこの do {} while (0) の意図は理解できないと思います。linuxカーネル以外でも頻出のCマクロのイディオムなので、覚えておいて損はないと思います。
ジェネリックプログラミング
さきほどのswap()の例をもう一度見てみましょう。
#define swap(a, b) \
do { typeof(a) __tmp = (a); (a) = (b); (b) = __tmp; } while (0)
これはインライン関数で実装しても同じように見えますが、実際やってみると面倒なことがわかります。以下のコードを見て下さい。
static inline void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
これはこれで動くのですが(引数に変数でなく変数へのポインタを指定しないといけないところは異なります)、このswap()はintにしか使えません。別の型については別のswap()を定義する必要があります。しかも、Cは関数のオーバーロード機能1が無いため、複数の型に対するswap()を同時に定義したい場合は、例えば次のように定義する必要があります。
static inline void swap_int(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
static inline void swap_double(double *a, double *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
呼び出すためにいちいち型名を指定する必要がある上に、同じような意味のコードを重複して書く必要があるので保守性が非常に悪いです。マクロを使えばこのような問題を避けられます。ちょうどC++のテンプレートを使ったジェネリックプログラミングのようなことができます。
ビルドの設定に応じて何もしない関数/マクロを定義する
linuxカーネルでは、特定のビルド設定において、特定の関数を何もしないように定義している箇所が多々あります。次に示す実際のコードを見てみましょう。
...
#if BITS_PER_LONG==32 && defined(CONFIG_SMP)
#include <linux/seqlock.h>
#define __NEED_I_SIZE_ORDERED
#define i_size_ordered_init(inode) seqcount_init(&inode->i_size_seqcount)
#else
#define i_size_ordered_init(inode) do { } while (0)
#endif
...
このコード断片は、ぱっと見ややこしそうですが、言葉で説明すると次のようなことをしています。
- i_size_ordered_init()というマクロを定義する
- ビルド対象アーキテクチャのlongのサイズが32であり、かつ、マルチプロセッサ環境であればseqcount_init()を呼ぶ
- そうでなければ何もしない
注目してもらいたいのはi_size_ordered_init()マクロのdo { } while (0)という定義です。これは先程の例の応用で、「何もしない」関数/マクロを定義しています。
このマクロを呼び出している箇所でいちいち
...
{
...
#if BITS_PER_LONG==32 && defined(CONFIG_SMP)
i_size_ordered_init();
#endif
...
}
...
などとするよりはるかにコードの保守性が高いです。
なお、#define i_size_ordered_init(inode)(マクロ定義を空にする)や、#define i_size_ordered_init(inode) {}などという定義にすると、前述のようなさまざまなコーナーケースが存在してしまいます。
引数の文字列化
次は、マクロの引数を文字列にする方法について学んでみましょう。例として、以下のlinuxカーネル内のコードを示します。
... #ifdef CONFIG_SCHED_DEBUG #define SCHED_WARN_ON(x) WARN_ONCE(x, #x) #else ... #endif ...
ここでは簡単のためCONFIG_SCHED_DEBUGが定義されていると考えて、SCHED_WARN_ON()マクロが何をするものなのかを見ていきます。このマクロは、スケジューラのコードの中で、スケジューラが異常な状態であることを示す条件を満たした(満たしてしまった)ときにカーネルのログに、どの条件文が成立したかを示す警告メッセージを表示するためのものです。
SCHED_WARN_ON()の中で使われているWARN_ONCE()マクロは、第一引数に指定された条件が満たされたときに、第二引数に指定されたデバッグ用メッセージを出力します2。
SCHED_WARN_ON()を素直に実装、使用しようとすると次のようになります(実際のものとは異なります)。
#define SCHED_WARN_ON(x, msg) WARN_ONCE(x, msg)
...
{
...
SCHED_WARN_ON(number_of_runnanble_processes < 0, "number_of_runnable_processes < 0");
...
}
...
これで一応目的を達成できるのですが、一見してわかるように、なんだかダサいです。同じテキスト("number_of_runnable_processes < 0")を二回書かなくてはいけないため、書くのが面倒な上に、条件を変えたときにメッセージの追従を忘れたりする可能性があり、保守性が悪いです。これを避けるのがCマクロの、引き数の文字列化機能です。
引数の文字列化機能は、マクロの引数の前に"#"という演算子を付けることによって実現します。たとえば#define tokenize(a) #aとマクロを定義すると、tokenize(test)は"test"と評価されます。上記の実際のSCHED_WARN_ON()は、これを応用して、第一、そして唯一の引数に条件文を渡すことで、当該条件を満たした際に、条件式を示す文字列をログに出力できます。
実際の使用例は次の通りです。
...
#define SCHED_WARN_ON(x) WARN_ONCE(x, #x)
...
static inline struct cpuidle_state *idle_get_state(struct rq *rq)
{
SCHED_WARN_ON(!rcu_read_lock_held());
return rq->idle_state;
}
...
cpuidle_state()関数の定義はプリプロセッサによって次のように変換されます。
static inline struct cpuidle_state *idle_get_state(struct rq *rq)
{
WARN_ONCE(!rcu_read_lock_held(), "!rcu_read_lock_held()");
return rq->idle_state;
}
上記の素直な実装例よりはるかに書くのが楽で、かつ保守性の高いコードになることがわかります。
トークンの連結
Cのマクロ定義の中では、2つのトークン3の連結によって新たなトークンを生成できます。これは文字列の連結とは全く異なります。以下のサンプルコードをごらんください。
#define concat_token(a) \
static int func_##a(void) \
{ \
return 0; \
}
concat_token(foo)
int main(void)
{
return func_foo();
}
先頭のconcat_token()マクロの定義の中のfunc_##aという箇所に注目してください。これは"func_"というトークンと、引数aで示したトークンの2つを連結したトークンを作るという意味です。多分意味不明だと思うので、実例を見てみましょう。
conat_token(foo)を評価した場合、func_##aはfunc_fooになります。その後、マクロ全体の評価結果は次のようになります。
static int func_foo(void) \
{ \
return 0; \
}
ソース全体をプリプロセッサにかけてみましょう。
$ cc -E concat_token.c
...
static int func_foo(void) { return 0; }
int main(void)
{
return func_foo();
}
$
func_foo()という関数が定義されていることがわかります。つまりこのマクロは、引き数に指定したトークン(ここでは"foo")を含む関数を定義するものであることがわかります。
これだけでは用途がわかりにくいので、linuxカーネル内の使用例を見てみましょう。
...
#define EXT4_FEATURE_COMPAT_FUNCS(name, flagname) \
static inline bool ext4_has_feature_##name(struct super_block *sb) \
{ \
return ((EXT4_SB(sb)->s_es->s_feature_compat & \
cpu_to_le32(EXT4_FEATURE_COMPAT_##flagname)) != 0); \
} \
static inline void ext4_set_feature_##name(struct super_block *sb) \
{ \
EXT4_SB(sb)->s_es->s_feature_compat |= \
cpu_to_le32(EXT4_FEATURE_COMPAT_##flagname); \
} \
static inline void ext4_clear_feature_##name(struct super_block *sb) \
{ \
EXT4_SB(sb)->s_es->s_feature_compat &= \
~cpu_to_le32(EXT4_FEATURE_COMPAT_##flagname); \
}
...
一見複雑ですが、実はやっていることは単純です。これはext4ファイルシステム内の各機能(mkfs.ext4(8)やtune2fs(8)の-Oオプションによって有効/無効を設定)に関する関数を一括定義するためのマクロです。第一引数nameが示す機能について、第二引数flagnameによって示すフラグを操作する、一連の関数を定義します。
例えば次のように使用します。
EXT4_FEATURE_COMPAT_FUNCS(dir_prealloc, DIR_PREALLOC)
これは次のように展開されます。
...
static inline bool ext4_has_feature_dir_prealloc(struct super_block *sb) \
{ \
return ((EXT4_SB(sb)->s_es->s_feature_compat & \
cpu_to_le32(EXT4_FEATURE_COMPAT_DIR_PREALLOC)) != 0); \
} \
static inline void ext4_set_feature_dir_prealloc(struct super_block *sb) \
{ \
EXT4_SB(sb)->s_es->s_feature_compat |= \
cpu_to_le32(EXT4_FEATURE_COMPAT_DIR_PREALLOC); \
} \
static inline void ext4_clear_feature_dir_prealloc(struct super_block *sb) \
{ \
EXT4_SB(sb)->s_es->s_feature_compat &= \
~cpu_to_le32(EXT4_FEATURE_COMPAT_DIR_PREALLOC); \
}
上記3つの関数の定義はそれぞれ次の通りです。
- ext4_has_feature_dir_prealloc: 引数sbで指定したext4ファイルシステムがdir_prealloc機能4を持っているかどうかを判定
- ext4_set_feature_dir_prealloc: 同機能を有効化
- ext4_clear_feature_dir_prealloc: 同機能を無効化
一見3つの関数をマクロ内で定義するなどという回りくどいことをせずに直接定義したほうが簡単そうに見えますが、同じような定義が何度も続くような場合にこのマクロは大きな威力を発揮します。実際、ext4のdir_prealloc以外の様々な機能について同様な定義が必要であり、それぞれについて上記のEXT4_FEATURE_COMPAT_FUNCS()マクロ5で一括定義しています。これによって膨大な量の機械的なつまらないコーディングを減らせます。
EXT4_FEATURE_COMPAT_FUNCS(dir_prealloc, DIR_PREALLOC) EXT4_FEATURE_COMPAT_FUNCS(imagic_inodes, IMAGIC_INODES) EXT4_FEATURE_COMPAT_FUNCS(journal, HAS_JOURNAL) EXT4_FEATURE_COMPAT_FUNCS(xattr, EXT_ATTR) EXT4_FEATURE_COMPAT_FUNCS(resize_inode, RESIZE_INODE) EXT4_FEATURE_COMPAT_FUNCS(dir_index, DIR_INDEX) EXT4_FEATURE_COMPAT_FUNCS(sparse_super2, SPARSE_SUPER2)
トークンの連結は一見便利そうですが、cscopeなどのツールが、マクロによって生成される変数や関数をうまく認識してくれずに、ソースコードリーディングが面倒になるなどという欠点もあります。cscopeなどを使って関数やマクロの定義を探しても全く出てこないという場合は、##演算子を使って定義されたものであるかどうかを疑ってみるとよいと思います。
構造体のフィールドから、それを埋め込んだ親構造体へのポインタを得る
次に示すのは、ある構造体のフィールドから、それを埋め込んでいる親構造体へのポインタを得るマクロです。
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
ptr(第一引数)がmember(第三引数)というフィールド名で埋め込まれたtype(第二引数)型のデータのアドレスを求めます。まずは、どうやってこのような機能を実装しているかを、これから紐解いていきます。
container_of()の中にあるoffsetof()の定義を示します6。
... #define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER) ...

このマクロによって、TYPE(第一引数)で示される構造体の中のMEMBER(第二引数)フィールドのバイト単位のオフセットが求められます。このマクロは、ゼロ番地に配置したTYPE型データの中のMEMBERフィールドのアドレス(をsize_t型にキャストしたもの)はTYPE内のMEMBERのオフセットに等しいという性質を利用しています。わかってしまえば簡単なのですが、初見ではけっこう意味不明で引いてしまうかもしれません。
これを踏まえてcontainer_of()の定義を再度見てみましょう。
...
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
一行目はちょっと回りくどく見えますが、単に mptr変数にptr(第一引数)を代入しているだけです。二行目では mptr(すなわちptr)から、type内のmemberのオフセットを引いています。つまり、これでptrの埋め込み元であるtype型のデータが求まってしまうということです。一見一行目を省いて二行目を(type *)((char *)ptr - offsetof(type,member))だけにすれば済みそうに見えますが、一行目によって、ptrとmemberの型の対応が取れていない場合に警告メッセージが出るようになっており、思わぬバグを防げるようになっています。

例によって、これだけでは何が嬉しいのかよくわからないので、linuxカーネルのファイルシステムのコードを実例として紹介します。
linuxカーネルにおいて、ファイルシステムのコードはVirtual File System層(以後VFS層と記載)という全ファイルシステム(ext4, XFS, Btrfsなど)共通のコードと、各ファイルシステム固有のコードに分かれています。たとえば全ファイルシステムに共通するinodeに関する情報はVFS層に存在するstruct inodeという構造体によって表現します。これに対して、各ファイルシステムは、自身固有のinode情報を含む構造体を持っており、その中にstruct inodeを埋め込んでいます。
Btrfsを例にとって説明すると、btrfs固有のinode情報はstruct btrfs_inode構造体に格納されます。そのうちファイルシステム共通の部分、つまりさきほど述べたstruct inodeは、この構造体の中のvfs_inodeというフィールドとして埋め込まれています。
...
struct btrfs_inode {
...
struct inode vfs_inode;
};
...

Btrfs内のinodeの各種時刻([cma]time)を更新する際は、VFS層からbtrfs_update_time()という関数が呼ばれます。
static int btrfs_update_time(struct inode *inode, struct timespec *now,
int flags)
{
struct btrfs_root *root = BTRFS_I(inode)->root;
...
}
この関数のインターフェイスはBtrfsを含む個々のファイルシステムではなくVFS層によって定義されていますので、その引き数によって渡されるinode情報は必然的にstruct btrfs_inodeではなく、struct inodeになります。しかし、Btrfsとしては時刻の更新に伴って後者だけではなく前者の情報を使って処理をする必要があります。
ではどうすればいいかというと、ここでcontainer_of()が登場します。btrfs_update_time()冒頭のBTRFS_I()の中で、container_of()を呼び出すことによって、inode(第一引数)をvfs_inode(第三引数)というフィールド名で埋め込んでいるstruct btrfs_inode(第二引数)のアドレスを求めます。
static inline struct btrfs_inode *BTRFS_I(struct inode *inode)
{
return container_of(inode, struct btrfs_inode, vfs_inode);
...
}
後は求めたstruct btrfs_inodeのデータへのポインタを使って粛々と処理をするだけです。具体的にどういう処理をするかは本書の対象範囲外なので割愛します。
リスト操作
linuxカーネルは、その中にstruct list_headという構造体によって管理する双方向リストの実装を持っています。このリストは例によって、C言語のマクロを最大限に活用して実装されています。この節ではその実装について扱います。
リストについての基本的な知識は、お手数ですが別記事の"リストの構造"という節に書いていますので、そちらを参照してください。短いし単純なので、短時間で読めると思います。
リストを処理するためのマクロは多くありますが、ここではその中でマクロを活用している処理について2つ紹介します。
まずは指定したstruct list_headのデータから、それを埋め込んだ親構造体を求めるlist_entry()マクロです。
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
これは定義を聞いただけでピンと来るかもしれませんが、内部でcontainer_of()を呼び出しているだけです。これでptr(第一引数)をmember(第三引数)というフィールド名で埋め込んでいるtype型のデータへのポインタを獲得できます。
続いて、リスト内の全エントリを順番に処理するlist_for_each_entry()マクロを見てみます。
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_head within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
この関数は、headで示されるリストの中の全要素について、各要素をposという名前で取り出すことによってそれぞれに対して処理をします。ここで、posの中でheadに対応するリストはmemberというフィールド名で埋め込まれています。
使用例を示します。サンプルプログラムの仕様とソースは次の通りです。
仕様:
- mylistというリストがある
- mylist内のエントリはint型のnという名前の唯一のデータを持つ
- mylist_show()は、mylist内のすべてのエントリに対してnをカーネルログに出力する
static LIST_HEAD(mylist);
struct mylist_entry {
struct list_head list;
int n;
};
...
static void mylist_show(void) {
struct mylist_entry *e;
printk(KERN_ALERT "mylist: show contents\n");
list_for_each_entry(e, &mylist, list) {
printk(KERN_ALERT "\t%d\n", e->n);
}
}
一見関数のように見える list_for_each_entry()マクロからブロックが生えてその中で処理をしているというのはC言語を知っていれば知っているほど驚くと思いますが、前述のようなマクロ定義をしていればこのような芸当が可能なのです。
linuxカーネルの中には他にも"for_each"という文字列を含む名前の類似のマクロが随所に出てきます。たとえば各エントリの処理中にエントリの削除が可能なlist_for_each_safe()があります。他にも、リストとは別のデータ構造にも類似したAPIが用意されていることもあります。興味があれば、それぞれの定義を見てみると面白いと思います。
おわりに
本記事は執筆時点で自分の脳内にたまたま残っていたマクロについて書いただけなので、他にも面白いマクロはいくらでもあると思います。思い出したらまた追記する予定です。読者のかたがたも、「これも紹介してくれ」とか「このマクロの意味がわからないんだけど」などありましたら、教えていただけると、今後追記するかもしれません。
-
同じ名前で別の引数、戻り値を持つ関数を定義できる機能。例えばswap(int a, int b)とswap(double a, double b)が共存できる。Cでこれをやろうとすると、同名関数が2つ定義されているという旨のコンパイルエラーが出ます。↩
-
最初に条件を満たしたときのみ出力されます。それ故に
_ONCEという名前が付いています)。↩ -
トークンという言葉がよくわからなければ、ここではなんとなく、コンパイラに変数名や関数名と解釈される文字列と考えてもらっていいです。↩
-
ここでは機能そのものの意味は重要ではないので割愛↩
-
より正確には、これに加えてEXT4_FEATURE_RO_COMPAT_FUNCS()マクロ、およびEXT4_FEATURE_INCOMPAT_FUNCS()マクロも用いる。↩
-
実際には下記定義を直接使うのではなくコンパイラ(通常gcc)組み込みの同等機能を使うのですが、理解を簡単にするためにこちらを例に使います。↩
カーネルモジュール作成によるlinuxカーネル開発入門 - 第四回 リスト
はじめに
本記事は第三回の続きです。前回までの記事を既に見ていることが前提です。
今回はカーネル内の代表的なデータ構造であるリストについて学びます。その過程で、カーネル内においてメモリを動的に割り当てる方法についても学びます。
リストの構造
リストの構造体の定義は次の通り、双方向リストです。
struct list_head { struct list_head *next, *prev; };
見てわかるように、リストそのものには数値、文字列などの実要素を埋め込むようなフィールドは用意されていません。かわりに、リストそのものを構造体に埋め込むという使い方をします。やや使い方に癖がありますが、慣れてくると非常に便利です1。
では、例としてmylistという名前がついた空のリストがあるとします。リストは次のように初期化します。
static LIST_HEAD(mylist);
行頭のstaticは、リストをモジュール内でのみ使う場合に指定します。そうでない場合はつけなくて構いません。他のモジュールに変数を公開する方法についてはあとの章で述べる予定です。
mylistは次の図のような双方向の構造をしています。

このmylistはnという名前の数値のフィールドをひとつ持つとしましょう。この場合、次のように当該リストのエントリ用の構造体を作成します。
struct mylist_entry { struct list_head list; int n; };
データ構造に直接 pref, next などのリンク構造を示すフィールドを用意せずにリスト専用のデータ構造を埋め込むことによって、このリストを使うあらゆるデータ構造に対して、リストを操作するAPIを1つに統一できるという利点があります。
このリストが1という数値を持つエントリをひとつだけ持つ時、リストは次のような構造になります。

同、1,10,100という3つの数値を持つエントリの場合、次のようになります。

いずれのリストも、リストそのものを示すmylistは意味のある値を全く持たないことに注意してください。
最も単純なリストの使用方法
リストの使用方法を学ぶために、次のようなモジュールを作ります。
- 要素に数値を持つリストを作成する
- モジュールロード時に空のリストmylistに次のような操作をする
- 先頭に1を追加
- 先頭に2を追加
- 先頭に3を追加
- 先頭から2つの要素を削除
- 末尾に4を追加
- 先頭から2つの要素を削除して空にする
- 操作するたびにカーネルログに操作内容と操作後のリストの内容を表示する
ソースは次の通りです。
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/list.h>
MODULE_LICENSE("GPL v2");
MODULE_AUTHOR("Satoru Takeuchi <satoru.takeuchi@gmail.com>");
MODULE_DESCRIPTION("an example of list data structure");
static LIST_HEAD(mylist);
struct mylist_entry {
struct list_head list;
int n;
};
static void mylist_add(int n) {
struct mylist_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add(&e->list, &mylist);
printk(KERN_ALERT "mylist: %d is added to the head\n", n);
}
static void mylist_add_tail(int n) {
struct mylist_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add_tail(&e->list, &mylist);
printk(KERN_ALERT "mylist: %d is added to the head\n", n);
}
static void mylist_del_head(void) {
struct mylist_entry *e = list_first_entry(&mylist, struct mylist_entry, list);
int n = e->n;
list_del(&e->list);
kfree(e);
printk(KERN_ALERT "mylist: %d is deleted from the head\n", n);
}
static void mylist_show(void) {
struct mylist_entry *e;
printk(KERN_ALERT "mylist: show contents\n");
list_for_each_entry(e, &mylist, list) {
printk(KERN_ALERT "\t%d\n", e->n);
}
}
static int mymodule_init(void) {
mylist_show();
mylist_add(1);
mylist_show();
mylist_add(2);
mylist_show();
mylist_add(3);
mylist_show();
mylist_del_head();
mylist_show();
mylist_del_head();
mylist_show();
mylist_add_tail(4);
mylist_show();
mylist_del_head();
mylist_show();
mylist_del_head();
mylist_show();
return 0;
}
static void mymodule_exit(void) {
/* Do nothing */
}
module_init(mymodule_init);
module_exit(mymodule_exit);
重要なポイントは次の通りです。
- kmalloc()によって動的にメモリを獲得する(ユーザプログラムにおけるmalloc()に相当)。第二引数はメモリ獲得時の諸条件を指定するフラグ。通常GFP_KERNEL。現段階ではあまり気にしなくて良い(後の章で説明予定)
- list_add()によって新規エントリをリスト先頭に追加
- list_add_tail()によって新規エントリをリスト末尾に追加
- list_del()によってエントリをリストから追加(本関数にリストそのものは指定しなくてよいことに注意)
- list_for_each()によってリストの全要素にアクセス
- list_for_each_safe()はlist_for_each()とほぼ同じだが、参照中のエントリを削除しても次の要素を安全に辿れる
- list_first_entry()によってlistの最初の要素を得る
このモジュールをロードすると次のようなログが出力されます。
# dmesg ... [ 6010.587046] mylist: show contents [ 6010.588791] mylist: 1 is added to the head [ 6010.590596] mylist: show contents [ 6010.592209] 1 [ 6010.593883] mylist: 2 is added to the head [ 6010.595695] mylist: show contents [ 6010.597318] 2 [ 6010.598625] 1 [ 6010.600152] mylist: 3 is added to the head [ 6010.601875] mylist: show contents [ 6010.603381] 3 [ 6010.604584] 2 [ 6010.605776] 1 [ 6010.606951] mylist: 3 is deleted from the head [ 6010.608662] mylist: show contents [ 6010.610167] 2 [ 6010.611347] 1 [ 6010.612476] mylist: 2 is deleted from the head [ 6010.614083] mylist: show contents [ 6010.615488] 1 [ 6010.617240] mylist: 4 is added to the head [ 6010.618830] mylist: show contents [ 6010.620254] 1 [ 6010.621378] 4 [ 6010.622476] mylist: 1 is deleted from the head [ 6010.624078] mylist: show contents [ 6010.625443] 4 [ 6010.626501] mylist: 4 is deleted from the head [ 6010.628052] mylist: show contents #
リストを使ったスタックの実装
前節のように、モジュールロード時に処理が全て終わってしまうのはあまり面白くないので、以前学んだdebugfsと今回学んだリストを用いて、ユーザから操作できるスタックをカーネル内に実装してみます。仕様は次の通りです。
- /sys/kernel/debugfs/mystack/以下にインターフェイスを持つ(以下このファイルを単にmystack/と表記)
- mystack/ 以下のファイルによって数値を格納するスタックを操作する。初期状態のスタックは空
- mystack/show からスタックの全要素を示す文字列を読み出す。要素間は空白で区切り、文字列の末尾には改行を置く
- mystack/push に数値を示す文字列を書き込むと、スタックの先頭に対応する要素を追加する。一度に追加できる要素の数は1つ
- mystack/pop を先頭から読み出すと、スタックの先頭要素を示す文字列を読み出した上で当該要素を削除する。先頭以外から読み出すと、何もせずに終了
コードは次の通りです。
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/debugfs.h>
MODULE_LICENSE("GPL v2");
MODULE_AUTHOR("Satoru Takeuchi");
MODULE_DESCRIPTION("a stack example implemented with list");
struct mystack_entry {
struct list_head list;
int n;
};
static LIST_HEAD(mystack);
static void mystack_push(int n) {
struct mystack_entry *e = kmalloc(sizeof(*e), GFP_KERNEL);
e->n = n;
list_add(&e->list, &mystack);
}
static int mystack_pop(int *np) {
struct mystack_entry *e;
if (list_empty(&mystack))
return -1;
e = list_first_entry(&mystack, struct mystack_entry, list);
if (np != NULL)
*np = e->n;
list_del(&e->list);
kfree(e);
return 0;
}
static void mystack_clean_out(void) {
while (!list_empty(&mystack)) {
mystack_pop(NULL);
}
}
static struct dentry *mylist_dir;
static struct dentry *showfile;
static struct dentry *pushfile;
static struct dentry *popfile;
static char testbuf[1024];
static ssize_t show_read(struct file *f, char __user *buf, size_t len, loff_t *ppos)
{
char *bufp = testbuf;
size_t remain = sizeof(testbuf);
struct mystack_entry *e;
size_t l;
if (list_empty(&mystack))
return simple_read_from_buffer(buf, len, ppos, "\n", 1);
list_for_each_entry(e, &mystack, list) {
int n;
n = snprintf(bufp, remain, "%d ", e->n);
if (n == 0)
break;
bufp += n;
remain -= n;
}
l = strlen(testbuf);
testbuf[l - 1] = '\n';
return simple_read_from_buffer(buf, len, ppos, testbuf, l);
}
static ssize_t push_write(struct file *f, const char __user *buf, size_t len, loff_t *ppos)
{
ssize_t ret;
int n;
ret = simple_write_to_buffer(testbuf, sizeof(testbuf), ppos, buf, len);
if (ret < 0)
return ret;
sscanf(testbuf, "%20d", &n);
mystack_push(n);
return ret;
}
static ssize_t pop_read(struct file *f, char __user *buf, size_t len, loff_t *ppos)
{
int n;
if (*ppos || mystack_pop(&n) == -1)
return 0;
snprintf(testbuf, sizeof(testbuf), "%d\n", n);
return simple_read_from_buffer(buf, len, ppos, testbuf, strlen(testbuf));
}
static struct file_operations show_fops = {
.owner = THIS_MODULE,
.read = show_read,
};
static struct file_operations push_fops = {
.owner = THIS_MODULE,
.write = push_write,
};
static struct file_operations pop_fops = {
.owner = THIS_MODULE,
.read = pop_read,
};
static int mymodule_init(void)
{
mylist_dir = debugfs_create_dir("mystack", NULL);
if (!mylist_dir)
return -ENOMEM;
showfile = debugfs_create_file("show", 0400, mylist_dir, NULL, &show_fops);
if (!showfile)
goto fail;
pushfile = debugfs_create_file("push", 0200, mylist_dir, NULL, &push_fops);
if (!pushfile)
goto fail;
popfile = debugfs_create_file("pop", 0400, mylist_dir, NULL, &pop_fops);
if (!popfile)
goto fail;
return 0;
fail:
debugfs_remove_recursive(mylist_dir);
return -ENOMEM;
}
static void mymodule_exit(void)
{
debugfs_remove_recursive(mylist_dir);
mystack_clean_out();
}
module_init(mymodule_init);
module_exit(mymodule_exit);
コード量は若干多いですが、これまでに学んだdebugfsとlistの使い方を知っていれば、それほど難しくないです。以下にポイントを示します。
- list_empty()によってリストが空かどうかを確認する。空なら1, そうでなければ0を返す
使用例を以下に示します。
root@packer-qemu:/home/vagrant# ls /sys/kernel/debug/mystack ls: cannot access '/sys/kernel/debug/mystack': No such file or directory root@packer-qemu:/home/vagrant# insmod /vagrant/list2.ko root@packer-qemu:/home/vagrant# ls /sys/kernel/debug/mystack pop push show root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/show; for ((i=0;i<5;i++)) ; do echo $i >/sys/kernel/debug/mystack/push; cat /sys/kernel/debug/mystack/show; done 0 1 0 2 1 0 3 2 1 0 4 3 2 1 0 root@packer-qemu:/home/vagrant# for ((i=0;i<5;i++)) ; do cat /sys/kernel/debug/mystack/pop; done 4 3 2 1 0 root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/show root@packer-qemu:/home/vagrant# cat /sys/kernel/debug/mystack/pop root@packer-qemu:/home/vagrant#
うまく動いているようです。他にも自分で色々動かしてみて下さい。
重大バグ
既に気づいたかたがいるかもしれませんが、このスタックはサイズに制限が無いので、ユーザから無制限に値をpushできてしまいます。そのたびにカーネル内の対応するデータ構造をメモリ上に確保します。このようなことをすると、カーネルの空きメモリをゼロになるまで食いつぶそうとするため、その過程でいわゆる Out of Memory(OOM)が発生します。そうするとデフォルトではOOM killerというカーネルの処理が走り、カーネルが選んだ適当なプロセスを殺戮してメモリの空き容量を増やそうとします。
次のようなコマンドの実行中に別のshellからVMのシリアルコンソールを覗いた結果を示します。
root@packer-qemu:/home/vagrant# for ((i=0;i=1000000000;i++)) ; do echo $i >/sys/kernel/debug/mystack/push; done```
コマンドを実行してしばらく経つと、シリアルコンソールに次のようなメッセージが表示されます。
$ virsh console elkdat_ktest ... [94417.067862] Kernel panic - not syncing: Out of memory and no killable processes... [94417.067862] [94417.067864] CPU: 0 PID: 1 Comm: systemd Tainted: G W O 4.9.0-ktest #1 [94417.067864] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.9.3-20161025_171302-gandalf 04/01/2014 [94417.067866] ffffbbfa000d2dd8 ffffffffaa3ffa12 ffffffffaae0e500 ffffffffaac802f8 [94417.067867] ffffbbfa000d2e60 ffffffffaa19bfb8 ffff9e7600000008 ffffbbfa000d2e70 [94417.067868] ffffbbfa000d2e08 00000000fd454624 00000000000000b5 0000000000000000 [94417.067869] Call Trace: [94417.067871] [<ffffffffaa3ffa12>] dump_stack+0x63/0x81 [94417.067874] [<ffffffffaa19bfb8>] panic+0xe4/0x22d [94417.067876] [<ffffffffaa1a2e9b>] out_of_memory+0x33b/0x490 [94417.067877] [<ffffffffaa1a82c4>] ... [94417.067988] [<ffffffffaa22f635>] SyS_write+0x55/0xc0 [94417.067990] [<ffffffffaa243159>] ? SyS_ioctl+0x79/0x90 [94417.067992] [<ffffffffaa84a2bb>] entry_SYSCALL_64_fastpath+0x1e/0xad [94417.068363] Kernel Offset: 0x29000000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff) [94417.947136] ---[ end Kernel panic - not syncing: Out of memory and no killable processes...
メモリ大量獲得の真犯人であるmystackはカーネル内のデータ構造なので、いかなるプロセスを削除しようとも空きメモリ量は回復しません。このため、カーネルはどうすることもできなくなり、パニックしています。これはカーネルの処理に問題があるとシステム全体が正しく動作しなくなるという良い例です。この問題の修正については後述の演習として残しておきます。
演習問題
- mystackの長さを10に制限する。要素数が10の時にmystack/ に書き込むとEINVALを返す(mystack/push の書き込みハンドラが -EINVALを返せばよい)
- mystackの要素を数値ではなく文字列(char *)にする。要素ごとの文字列の長さ(strlen()の戻り値)は最長10
mystackを改造してmyqueueというキューを作成する
/sys/kernel/debug/myqueue(以下 myqueue/ と表記)がキューに対応
- 要素は数値
- キューの長さは最長10
- myqueue/show を読むことによって現在のリストの一覧を得られる
- myqueue/queue へ書き込んだ文字列に対応する数値(1つ)をキューの末尾に追加する
- myqueue/dequeue を読むことによってキューの先頭要素を得ると共に、当該要素をキューから削除する
おわりに
今回使ったソースはexample/module/list以下に置いています。実はmystackには、リスト長の問題を解決してなお、排他制御という観点から見て重大な問題があります。次回は排他制御の基本について述べます。その過程でこの問題も解決します。
参考資料
- カーネルソースのinclude/linux/list.h: 本章で紹介したもの以外にも沢山のリスト操作関数が定義されている。名前は”list_”で始まる
- LinuxにおけるOOM発生時の挙動
科学実験のようにスケジューラの挙動を観測する
はじめに
本書の主な対象読者はlinuxを含むOSのプロセススケジューラについて聞いたことがない人や、名前は知っているけど具体的に何をするものかをよく知らない人です。
linux kernelは複数プロセスを同時に動作させる(正確にはさせているように見せかける)ためのプロセススケジューラという機能を持っています。といっても、みなさんがlinuxシステムを使う場合は通常プロセススケジューラを意識しないで済むようになっています。では、あえて意識したい場合、どのような機能なのかを知ってみたい場合はどうすればよいのでしょうか。
kernel機能(ここではプロセススケジューラ)の挙動を明らかにするには、ソースを読む、色々ソース改変しながら動かしてみる1、などが有効です。しかし、ここでは一切ソースを読まずに、ユーザプロセスを使う実験のみによってカーネルの挙動を観測してみます。これは、まるで神様2の作った宇宙の仕組みを解き明かそうとする科学実験のようです。
コンピュータに関する本にはスケジューラについて、
- CPU上で同時に動けるプロセスは一つだけ
- 複数プロセスが実行可能な場合、個々のプロセスを適当な長さの時間(タイムスライスと呼びます)ごとにCPU上で順番に動かしている
などという文言が書いていることが多いですが、殆どの人は知らないか、あるいは何となく耳学問として知っているというだけではないでしょうか。本記事では、この文言を仮説とみなして、それが本当かどうかを自作プログラムを使った実験によって検証してみます。実際に「知っている」だけよりも「やって、確認した」ことによって、linux、ひいてはコンピューターシステムについて、より理解が深まると思います。
実験方法
まずは単一CPU上で、ひたすらCPUを使い続けるプロセスを複数個同時に動かし、その統計情報(ある時点でどのプロセスが動作していたか。及び、それぞれの進捗はどれだけか)を採取します。そのデータの分析によって、上述の仮説が正しいかどうかを検証します。
この目的を達成するために、次のような仕様のプログラムを作成します。
以下の引数を持つ
- n: 同時に動かすプロセス数
- total: 動作させる時間(マイクロ秒単位)
- resol: 1データごとの測定間隔(マイクロ秒単位)
n個のプロセスを同時に動作させ、それらが終了したらプログラム全体も終了する
それぞれのプロセスは次のような動作をする
- totalという時間CPUを使い続けた後に終了する
- resolという時間CPUを使うごとに、ID(0から始まるプロセスごとに固有の数値)、プログラム開始時点からの経過時間(マイクロ秒単位)、進捗(0〜1)を記録する
- 終了時に上記の統計情報を出力する
プログラムのソース
本記事で使用するソースはgithub上に置いています。
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <err.h>
#define NLOOP_FOR_ESTIMATION 10000000000L
static inline long diff_usec(struct timeval before, struct timeval after)
{
return (after.tv_sec * 1000000L + after.tv_usec)
- (before.tv_sec * 1000000L + before.tv_usec);
}
static double loops_per_usec()
{
long i;
struct timeval before, after;
if (gettimeofday(&before, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday(before) failed");
for (i = 0; i < NLOOP_FOR_ESTIMATION; i++)
;
if (gettimeofday(&after, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday(after) failed");
return NLOOP_FOR_ESTIMATION / diff_usec(before, after);
}
static inline void load(int nloop)
{
int i;
for (i = 0; i < nloop; i++)
;
}
static void child_fn(pid_t id, struct timeval *buf, int nrecord, int nloop_per_resol, struct timeval start)
__attribute__ ((noreturn));
static void child_fn(pid_t id, struct timeval *buf, int nrecord, int nloop_per_resol, struct timeval start)
{
int i;
for (i = 0; i < nrecord; i++) {
load(nloop_per_resol);
struct timeval tv;
if (gettimeofday(&tv, NULL) == -1)
err(EXIT_FAILURE, "gettimeofday() failed");
buf[i] = tv;
}
for (i = 0; i < nrecord; i++) {
printf("%d,%ld,%f\n", id, diff_usec(start, buf[i]), (double)(i+1)/nrecord);
}
exit(EXIT_SUCCESS);
}
static void parent_fn(int nproc)
{
int i;
for (i = 0; i < nproc; i++)
wait(NULL);
}
static struct timeval **logbuf;
static pid_t *pids;
int main(int argc, char *argv[])
{
int ret = EXIT_FAILURE;
if (argc < 4) {
fprintf(stderr, "usage: %s <nproc> <total[us]> <resolution[us]>\n", argv[0]);
exit(EXIT_FAILURE);
}
int nproc = atoi(argv[1]);
int total = atoi(argv[2]);
int resol = atoi(argv[3]);
if (nproc < 1) {
fprintf(stderr, "<nproc>(%d) should be >= 1\n", nproc);
exit(EXIT_FAILURE);
}
if (total < 1) {
fprintf(stderr, "<total>(%d) should be >= 1\n", total);
exit(EXIT_FAILURE);
}
if (resol < 1) {
fprintf(stderr, "<resol>(%d) should be >= 1\n", resol);
exit(EXIT_FAILURE);
}
if (total % resol) {
fprintf(stderr, "<total>(%d) should be multiple of <resolution>(%d)\n", total, resol);
exit(EXIT_FAILURE);
}
int nrecord = total / resol;
long pagesize = sysconf(_SC_PAGESIZE);
if (pagesize < 0)
err(EXIT_FAILURE, "sysconf() failed");
logbuf = malloc(nproc * sizeof(struct timeval *));
if (logbuf == NULL)
err(EXIT_FAILURE, "malloc(logbuf) failed");
int i, nallocated;
for (i = 0, nallocated = 0; i < nproc; i++) {
int ret_pma = posix_memalign((void **)&logbuf[i], pagesize, nrecord * sizeof(struct timeval));
if (ret_pma) {
errno = ret;
warn("posix_memalign() failed");
goto free_logbuf;
}
nallocated++;
if (mlock(logbuf[i], nrecord * sizeof(struct timeval))) {
warn("mlock() failed");
goto free_logbuf;
}
}
int nloop_per_resol = (int)(loops_per_usec() * resol);
pids = malloc(nproc * sizeof(pid_t));
if (pids == NULL) {
warn("malloc(pids) failed");
goto free_logbuf;
}
struct timeval start;
if (gettimeofday(&start, NULL) == -1) {
warn("gettimeofday(start) failed");
goto free_logbuf;
}
int ncreated;
for (i = 0, ncreated = 0; i < nproc; i++, ncreated++) {
pids[i] = fork();
if (pids[i] < 0) {
goto wait_children;
} else if (pids[i] == 0) {
// children
child_fn(i, logbuf[i], nrecord, nloop_per_resol, start);
/* shouldn't reach here */
}
}
ret = EXIT_SUCCESS;
// parent
wait_children:
if (ret == EXIT_FAILURE)
for (i = 0; i < ncreated; i++)
if (kill(pids[i], SIGINT) < 0)
warn("kill() failed");
for (i = 0; i < ncreated; i++)
if (wait(NULL) < 0)
warn("wait() failed.");
free_pids:
free(pids);
free_logbuf:
for (i = 0; i < nallocated; i++)
free(logbuf[i]);
free(logbuf);
exit(ret);
}
素直に仕様通りに実装したため、それほど難しいことはしていません。気になるかたのためにポイントをいつくか説明しておきます。
- mlock(2)によってデータを記録するバッファ(logbuf[])の物理メモリ上への貼り付けを強制し(物理メモリ上にlockし)、ページフォールトによる測定誤差を無くしています。
- ユーザ空間からカーネル空間への状態遷移無しに時間を測定できるgettimeofday(2)を用いることによって測定誤差を減らしています。他にもCPUのrdtsc命令などによってさらに誤差を減らすこともできますが、ここでは割愛
- loops_per_usec()では、1マイクロ秒CPUを使うのに必要なループの数を推定しています。適当な数(NLOOP_FOR_ESTIMATION)だけ何もしないループを回すのに要した所要時間を測定し、ループ数をその時間で割ることによって求めます。
なお、本記事はプログラムの実装について学ぶのが主目的ではないので、わからなくても気にする必要はありません。
今回は4CPU(正確には1CPU4コア)環境において、CPU3上でプログラムを同時に1〜4個動作させてみます。個々のプロセスごとに100msだけCPUを使います。その間のデータ測定の間隔は1msです。これを実現するためのスクリプトは次の通りです。
#!/bin/bash
NCPU=$(grep -c processor /proc/cpuinfo)
LASTCPU=$(($NCPU - 1))
PATTERN="1 2 3 4"
TOTAL_US=100000
RESOL_US=1000
for i in ${PATTERN} ; do
taskset --cpu-list ${LASTCPU} ./sched $i ${TOTAL_US} ${RESOL_US} >$i.txt
done
あとは make sched && ./captureによって結果が得られます。以下、注意点を示します。
- makeの際に最適化オプションを付けてしまうと、loops_per_sec()やload()の中のループ処理が、意味の無い処理として削除されてしまうことがあります。これらの処理は、人間から見ると「所定の時間だけCPUを使う」という意味のある処理なのですが、コンパイラからすると「論理的に意味の無い、無くても良い処理」とみなされる恐れがあるということです。このため、最適化はしないでください。
- 上記プログラムの実行中は測定誤差を避けるために、なるべく他のプロセスを実行しないでください3。
実験環境
- ハードウェア
- CPU: Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz x 1 (4 core 1 thread)
- RAM: 8GB
ソフトウェア
OS: 2017/2/2 時点での最新の Debian GNU/Linux stretch
- kernel: 4.8.0-1-amd64
測定結果
私の環境で得られた結果をもとにグラフを作成しました。並列度1〜4のそれぞれについて、
CPU上で動作中のプロセス
x軸: 開始時点からの経過時間[us]
y軸: はプロセスの番号(0〜3)
各プロセスの進捗
x軸: 上記グラフと同じ
- y軸: 進捗(0が何もしていない状態。1が完了状態。単調増加する)
という2つのグラフを描きました。筆者がグラフ作りに不慣れなために見た目がダサいですが、そこはご容赦。
プロセス数1
CPU上で動作中のプロセス

ただ一つ存在するp0が常に動作しています。total引数で指定した通り、およそ100ms後に全ての処理が終わります。これについては、仕事量見積もりの誤差やデータ測定のオーバーヘッドなどの理由によって、ちょうど100ms後にするのはなかなか難しいですが、頑張ればこの誤差はある程度は減らせます。興味のあるかたは後述の参考資料をごらんください。
各プロセスの進捗

p0以外に動作中のプロセスはいないため、進捗は単純に経過時間に比例します。
プロセス数2
CPU上で動作中のプロセス

p0, p1が交互にCPUを使っていることがわかります。全プロセスが同じ長さのタイムスライスを持っていると推測できます。処理完了までの経過時間はプロセス数1の場合のおよそ2倍です。それぞれのプロセスは単一CPUの計算能力を半分づつしか使えないので、これは当然の話です。
各プロセスの進捗

それぞれ自分がCPUを使っている間だけ処理が進捗し、それ以外、つまりCPU上で別のプロセスが動作している間は進捗がありません(グラフ上ではx軸にほぼ平行な線として現れる)。これは1つ上のグラフからなんとなく推測できることです。
また、ややカクカクしていますが、大まかに見るとp0, p1とも、プロセス数1の場合の線の傾きを半分にした直線に似た線になります。仮にそれぞれのプロセスがCPUを使えていない時間が気にならない、気づかない(数mmなどというのは人間にとって非常に小さな時間です)というのであれば、人間には二つのプロセスが同時に動いているように錯覚させられます。
プロセス数3
CPU上で動作中のプロセス

プロセス数2の場合と傾向は同じです。p0->p2->p1の順番にCPU実行権が遷移しています。タイムスライスはプロセス数2の場合に比べて短くなっているようです(これは生データの分析によってわかります)。終了までの経過時間は1プロセスの場合の約3倍です。
各プロセスの進捗

3プロセスになっても2プロセスの場合と傾向は同じです。
プロセス数4
CPU上で動作中のプロセス

これも他の場合と傾向は同じです。p0->p2->p1->p3の順にCPU実行権が遷移しています。タイムスライスはプロセス数3の場合に比べて、さらに短くなっているようです。終了までの経過時間はプロセス数1の場合の約4倍です。
各プロセスの進捗

これも他のものと傾向が同じです。
考察
実験結果から次のようなことがことがわかりました。
- 同時に何個のプロセスが実行可能状態で存在しようとも、1CPU上である瞬間に動作できるプロセスは1つだけ
- 複数プロセスの間でラウンドロビン形式でCPU実行権が移ってゆく
- タイムスライスはプロセス数が増加するほど減少する
スケジューラになじみのないかたがたにとっては、なかなかおもしろいデータだったのではないでしょうか。是非ご自分の環境でも試してみて下さい。さきほども言いましたが、人がやっているのを見るのと自分でやってみるのでは全然理解の深さが変わってきます。
終わりに
本書で実施したことに加えて、次のようなことをするとまた新たな面白い情報が得られます。興味のあるかたは挑戦してみてください。
- プロセス数に応じてタイムスライスがどのように変わるかの法則を明らかにする
- resolの値をタイムスライスより大きな値に増やしてみる
- 複数CPUで実行する: たとえば本記事で使用したtaskset(1)の--cpu-listオプションが使えます。例えば--cpu-list 2,3とすると、プロセスがCPU2,3のどちらかの上でのみ実行できるようになります。また、この場合にはresol毎の情報採取時に、sched_getcpu(3)を用いてプロセスが動作中のCPUの情報を追加採取するとよいでしょう
- nice値を変えたプロセスを動かしてみる
- リアルタイムプロセスで同じことをしてみる: chrt(1)コマンドが使えます
- CPUを使い続けるだけではなく、nanosleep(2)などによってスリープ処理を入れてみる
当初はこれらについては記事に盛り込むつもりでしたが、本記事を書くのが意外と大変だったため、力尽きました。続きは参考資料に挙げた「[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識」に書きました。
実はlinuxのプロセススケジューラはv2.6.23から大規模な書き直しをされており、このバージョン前後で挙動がかなり異なっています。たとえば本記事の実験においてタイムスライスはプロセス数に応じて減少しましたが、古いスケジューラでは別の挙動をします。興味のあるかたは、本記事で使用したプログラムを、古いスケジューラを採用するカーネル(v2.6.22以前。CentOSでいうと5.x以前が使用)で実行して結果を比較してみるのもよいと思います。
最後にもう一点だけ。ユーザ空間からだけでなくカーネルのスケジューラのソースも見ると神様の視点から直接カーネルの内部がわかって楽しいですよ。そこには観測したデータではなく、事実が直接書いています。ようこそカーネルの世界へ。
参考資料
- タスクスケジューラ用のsysctlパラメタ: スケジューラに関するsysctlパラメタに加えてスケジューラそのものの挙動についても少し説明しています
- Linux スケジューラーのコア実装とシステムコール: スケジューラのソースについての解説記事
- RHEL7のパフォーマンスチューニングガイドに記載の推奨設定: 本書に記載したような測定プログラムの精度を下げる敵である外乱(割り込み処理や測定用プロセス以外のプロセス)を減らすための方法について記載しています
- [試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識: プロセススケジューラの章において、複数CPU環境におけるスケジューリングの実験など、本記事の内容をさらに突っ込んだとことを説明しています
ソフトウェアのサポート業務とはどのようなものか
はじめに
ソフトウェアの世界にはいろいろな仕事があります。何も知らない人から見て一番脚光を浴びがちなのが開発者、とくにプログラマーでしょう。スーパープログラマーを題材とした漫画やアニメ、映画はたくさんあります。しかし、それ以外の仕事は実際やってみないと想像しづらいことより、あまり実情が知られていません。本記事ではそれらの中からサポートエンジニアに注目して、この職種がどういうものなのかについて書きました。対象読者は開発者、とくに自分で作ったものを自分ないし近しい人だけが使うという経験しかしていない駆け出しの開発者です。
サポートエンジニアといっても色々なものがありますが、ここではSI企業において顧客システムでトラブルが起きたときにSEの依頼を受けて問題を解決するエンジニア、という極めて単純な定義をしておきます。開発者がサポートエンジニアを兼ねるケースとそうでないケースの両方がありますが、本書ではどちらでもかまいません。
筆者はかつてSI企業において社会インフラを支えるような大きなシステムについてのLinuxカーネルの開発、サポートを数年経験しました。本記事はそんな筆者がこれまでに体験したこと、見聞きしたことをもとに書いています。筆者の経験は非常に狭い範囲についてのものなので本記事の内容が当てはまらない環境はいくらでもあるでしょうが、少なくともサポート経験者の一人からはこう見える、という観点で見ていただけたらと思います。
本記事を書いた動機は次のようなものです。
- サポート業務がなんであるか、どういう魅力があるのかについて知ってほしい
- 開発とサポートが相互に補完し合う、それぞれ別種の能力が必要であることを理解してほしい
- 上記を踏まえて、開発に比べてサポートが簡単な、一歩下のものであるとかいう雰囲気が1あるのを何とかしたい
前置きが長くなってしまいましたが、次節から具体的な話をします。
顧客およびSEの価値観を理解する
顧客およびSEの価値観(以降顧客とSEは価値観を共有しているものとして顧客の価値観と記載)がサポートエンジニアと異なっていることによって両者の会話がまったく成立しないということが多々あります。やや極端ですが、SEであるAさんと、開発者出身で最近サポートエンジニアになったBさんの例を考えてみましょう。二人の価値観は次のようなものです。
- Aさん価値観: トラブルなくサービスを継続できるのが好ましい
- Bさんの価値観: 好きなプログラミング言語を使って美しいコードを書くのが好ましい
すでに嫌な予感がプンプンしていますが、この不一致によって発生するのが以下のような世にも恐ろしい会話です。
- Aさん「先日報告した問題について現状を教えてほしい」
- Bさん「(ソースを見せながら)これはfooクラスのbarというメソッドがO(n)なのでnが増えたときにスケールしないことが問題です」
- Aさん「??? 問題はいつまでに解決する見込みでしょうか」
- Bさん「ここのコードは腐っているので1週間くらいかけて根本的に作り直したほうがいいです。」
- Aさん「なんとか影響を最小限におさえて短期間で仮修正ができないでしょうか」
- Bさん「そんなダサいことはしたくありません」
- Aさん「???」
ここでの問題は、システムのユーザはあくまで顧客であるのに対してBさんが顧客の価値観を無視して自分の好きなことを言っていることにあります。優秀とされるプログラマがサポート業務はまったくできないというのはよくある話ですが、そのうちの少なからぬ数がこれにあてはまります。
このようなことを避けるために、Bさんには相手の立場に立って顧客の価値観を第一に、自分の価値観は第二に考えるという発想の転換が必要でしょう。これがどうしてもできない、やりたくないという人は別の人にサポートを任せるとよいでしょう。ただしそのときに「自分の価値観を理解しないAは程度が低い」というような驕った考え方をするのではなく、「自分はコードは書けるがサポートはできない。自分とサポートエンジニアはお互いに補完し合おう」と考えるほうが建設的でしょう。
システムへの影響は最小限に
あるソフトウェアのバージョンアップによって何らかの問題が発生したとします。ここでは簡単のために前バージョンと現バージョンの間に100コミットあり、かつ、再現手順は明らかになっているものとします。このとき根本原因を知るための愚直ながら確度が高い方法のひとつにbisectというものがあります。具体的には、まず前バージョンから50コミット目で再現試験をして、問題が発生したら次は25コミット目で再現試験を…という手順を繰り返して対数オーダーで根本原因となるコミットを突き止めるという方法です2。
では顧客システムでバイナリサーチを試せるでしょうか。答えはほとんどの場合は否です。なぜかというと顧客システムでソフトウェアのバージョンを入れ替えるということは、そのたびにシステムが停止する、それによって顧客のサービスが停止するということを意味します。したがって、このようなことを何度も試させてくれるという可能性は低いでしょう。その他にも開発環境でしか使えないような性能劣化の激しいログやトレースの有効化などは、そうそう使わせてもらえないでしょう。このため、サポートエンジニアは常に問題の切り分けをするための手段を多く持っておく、および、それらがどのような条件で使えるかを把握しておく必要があります。
依頼は具体的に、数は最小に、意図は明確に
みなさんはご自身がお持ちの何らかの製品のサポートを受けたことが少なからずあると思います。そのときのことを考えてみてください。ただでさえ問題が発生していて面白くない気分なのに次から次へと新たな依頼をされたらどう思うでしょうか。おそらくは段々イライラしてくるのではないでしょうか。これと同じことがコンピュータシステムにおいても言えます。
SEへの依頼は回数が増えれば増えるほど相手の負の感情を増幅させます。それに加えて依頼の意図が不明であればあるほどSEのサポートエンジニアへの不信感が増えます。このようなことをを避けるために、SEへの依頼の数は最小限にして、かつ、それぞれの依頼は何をしたいがために何をしてほしいのかを明確にする必要があります。サポートエンジニアの依頼の裏にある意図を読み取って回答してきてほしいという安易な考え方は捨てましょう。
依頼回数についてもう少し細くしておきます。依頼回数に限りがあるなかで調査を進めるためには次のような方法があります。
- システム稼働時の要所要所でログをとる
- 同、メトリクスを採取する
- システムの異常終了時にコアダンプ(異常終了時のメモリの中身を保持したファイル)をとる
サポートエンジニアには、これらの状況証拠から逆算して根本原因を見つける探偵のような能力が必要になります。それに加えて依頼回数、およびその際の影響範囲を最小限におさえなければならないという制約もあります。この手の能力はプログラミング能力とはまた別種の能力であり、優秀なプログラマがトラブルシューティングは苦手ということはよくあります(その逆も然りです)。
どれも事後に仕掛けて再度再現を試みるのは大変ですので、可能な限り常に採取できるようにしておくとよいでしょう。
ログやメトリクスについては、採取するのは開発者であるものの、どのようなログやメトリクスがあれば調査が楽かはサポートの視点が必要です。このため、開発とサポートは密に連携してサービスレベルの向上に取り組むとよいでしょう。それに加えて開発者はサポートの視点を身につけるために一度はサポート業務を経験するとよいと筆者は考えます。実際筆者は両方経験したことによりソフトウェア技術者として大きく成長できたことを常々実感しています。
記憶ではなく記録をもとに調査する
SEへ問い合わせをする際は可能な限りソフトウェアの出力ベースで話をする必要があります。なぜかというと人は悪意が無くても無意識に嘘をつくからです。一番有名なのは「何もしてないのに壊れた」というやつです。典型的なのは以下のような会話です。
- SE「昨日から問題が発生するようになった」
- サポートエンジニア「問題発生前後で何かしましたか」
- SE「なにもしてない」
- 後日調査に疲れ果てたサポートエンジニア「(ソフトウェアのバージョン変わってるし…)」
このようなことを避けるために、確認はSEをはじめとする関係者の記憶に頼るのではなく、ソフトウェアのログなどの記録に頼るべきでしょう。たとえば上記の問答でいうとサポートエンジニアは「ソフトウェアのアップデートログを見せてください」などのようにするとよかったでしょう。これを踏まえて、システムの状態が変化するときにはどこにどのような記録が残るかについては押さえておくべきでしょう。
サポートが複数階層に分かれる場合
前節まではSEから問題発生時に特定コンポーネントに直接調査依頼が来るという想定でした。しかしシステムがある程度以上の規模になると複数階層になっていることがほとんどです。具体的にはSEが一次サポートエンジニアに調査依頼をすると、そこで切り分けをした上で関係していそうなコンポーネントのサポートエンジニアにさらに調査を振り分ける、というようになります。なぜこのようなことをするかというと、例えばシステムが二つのコンポーネントA,Bから構成されているとして、すべての問題報告がAとB両方のサポートエンジニアに降ってくると効率が悪いからです。
一次サポートエンジニアには開発者、および一つのコンポーネントのサポートエンジニアとはまったく別種の能力が必要になります。まず、特定のコンポーネントに対する深い知識というよりも、守備範囲となる複数のソフトウェアについての浅く広い知識が必要になります3。
一次サポートエンジニアは関係者の数が多いです。SEからの報告をもとに各コンポーネントのサポートに対して依頼をして、回答を得て、場合によっては督促をして、さらにSEに報告して…と、たくさんのタスクを同時並列でこなす必要があります。場合によっては先に進めるためにできることがなくなったように見える状態で関係者全員で協議する会を設けて調整をする必要も出てくるでしょう。
わたしは一次サポートエンジニアの経験は無いので確たることは言えませんが、サポートエンジニアをやるとして、システムのより広い範囲を見渡したい、そこで発生する物事の中心にいるハブになりたいようなかたは一次サポートが向いているのではないかと思います。
おわりに
サポートエンジニアは問題発生時に何が起きたかを証拠をもとに仮説を立ててそれを検証していく探偵のようなことを主にやりたい人には魅力的だと思います。また、サポートエンジニアを体験することによって、ソフトウェアを開発するときに何に気を付ければ問題解決が早まるか、および解決できる確率が高まるかということを身をもって知れるため、開発者として一皮むけるためにも有用です。
この記事を読んでサポートエンジニアがどのようなものであるのかがわかってくれる人、および自分もやってみようと思ってくれる人が増えることを願っています。また、問題発生時にSE、サポートエンジニア、開発者が一丸となって建設的に解決をめざすケースが増えることを祈っています。
たのしく学ぶLinuxカーネル開発(第一回): `rm -rf /`実行時にカーネルパニックさせる
はじめに
Linuxカーネル開発を学ぶためにhello worldモジュールからはじめて少しづつ強化する記事を過去にいくつか書きました。これはちゃんとやれば身に付くことは身に付くのですが、非常に地味なので、よほどカーネルに興味を持っている人以外には退屈でしょう。そこで、目的をもって特定の機能をカーネルならではの方法で実現する記事を書けば面白いのでは…となったのでここに初回を書くことにしました。
対象読者はCライクなプログラミング言語での開発経験がある人です。Cのポインタがわかればなおよし。もしできればOSカーネルについての基本的な知識も欲しいです。
背景
UNIXが誕生してから現在に至るまでrm -rf /によって全ファイルをぶっ飛ばす事件が後をたちません。GNUのcoreutilsに入っているrmではルートディレクトリ("/")への操作を特別扱いして容易に悲劇を起こさなくするpreserve-rootというデフォルトで有効になるオプションもあります。しかし人間とはこういうときにもこの機能を無効にする--no-preserve-rootをうっかり付けててしまうのです。
そこでユーザがrm -rf /を実行しようとするとカーネルパニックさせる(Windowsでいうところのブルースクリーンを出す)フェイルセーフ機能を作ることにしました。
対象とするカーネル
- linux v5.3
このカーネルのソースコードは以下コマンドによって取得できます。
$ git clone -b v5.3 --depth 1 https://github.com/torvalds/linux ... # 数GBのディスク容量を消費しますので、ご注意ください $ git checkout v5.3 ... $
変更点
この機能の変更点を示すパッチファイル0001-panic-if-user-tries-to-run-rm-rf.patchの中身は次の通りです(内容は後で説明します)。ライセンスはGPL v2です。
From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001 From: Satoru Takeuchi <satoru.takeuchi@gmail.com> Date: Sun, 6 Oct 2019 15:53:34 +0000 Subject: [PATCH] panic if user tries to run rm -rf / --- fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++ 1 file changed, 37 insertions(+) diff --git a/fs/exec.c b/fs/exec.c index f7f6a140856a..8d2c1441b64c 100644 --- a/fs/exec.c +++ b/fs/exec.c @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename, if (retval < 0) goto out; + // Panic if user tries to execute `rm -rf /` + if (bprm->argc >= 3) { + struct page *page; + char *kaddr; + char rm_rf_root_str[] = "rm\0-rf\0/"; + char buf[sizeof(rm_rf_root_str)]; + int bytes_to_copy; + unsigned long offset; + + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE); + page = get_arg_page(bprm, bprm->p, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + offset = bprm->p % PAGE_SIZE; + memcpy(buf, kaddr + offset, bytes_to_copy); + kunmap(page); + put_arg_page(page); + + if (bytes_to_copy < sizeof(rm_rf_root_str)) { + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0); + if (!page) { + retval = -EFAULT; + goto out; + } + kaddr = kmap(page); + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy); + kunmap(page); + put_arg_page(page); + } + + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str))) + panic("`rm -rf /` is detected"); + } + would_dump(bprm, bprm->file); retval = exec_binprm(bprm); -- 2.17.1
動かし方
最初に一点注意。この機能は壊してもいいVM上でやりましょう。動作確認テストが失敗すると全ファイルがぶっ飛びかねませんし、成功してもダーティなページキャッシュに乗っているデータは失うことになります。
まずは次のようにパッチファイルを適用した上でビルド、インストール、再起動します。
$ git apply 0001-panic-if-user-tries-to-run-rm-rf.patch ... # 機能追加に必要なパッチを当てる $ sudo apt install kernel-package flex bison libssl-dev ... # カーネルビルドに必要なパッケージをインストール $ make localmodconfig ... # ビルドのための設定をする。何か聞かれたらENTERを押しまくる $ make -j$(grep -c processor /proc/cpuinfo) ... # ビルドする $ sudo make modules_install && make install ... # 新しいカーネルとそのモジュールをインストールする $ sudo /sbin/reboot # GRUBで現在起動中のものなど特定のカーネルを次回起動するようになっている場合は適宜修正してください
再起動後にカーネルバージョンが変わっていることを確認します。
$ uname -r 5.3.0+ $
5.3.0+となっていれば成功です。最後の"+"はカスタムカーネルのときに勝手に付与されます。
最後に例のコマンドを実行します。
$ rm -rf /
これで応答が戻ってこなければ成功です。マシンのコンソールを見ている場合はパニック時のカーネルログが見られます。GUI上の端末エミュレータあるいはssh経由でコマンドを叩いた場合は単に画面が停止したように見えるでしょう。
参考までにわたしの環境での実行結果を載せておきます。
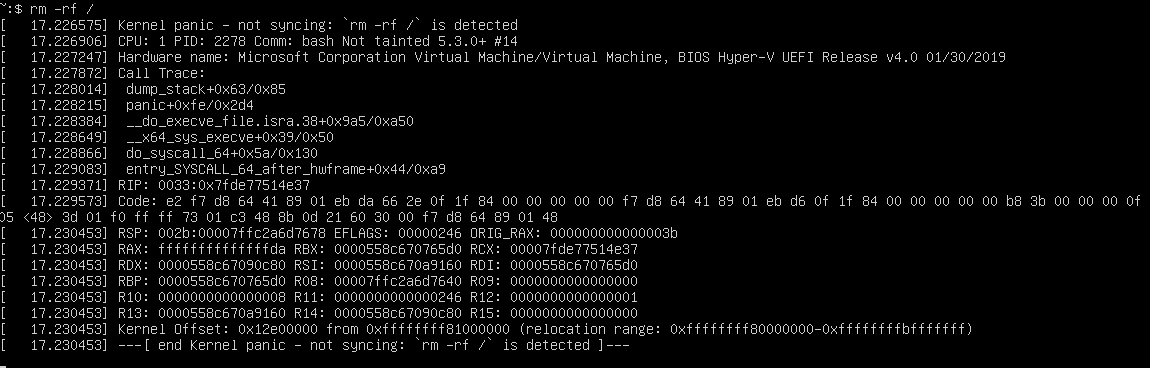
この機能はrm -rf /を誰が実行したかなどというものは考えておらず、ルートディレクトリ以下のファイルを消す権限が無い一般ユーザがこのコマンドを実行しても容赦なくカーネルパニックを起こしますのでご注意ください。
この後はマシンを再起動させて、必要ならば本記事によってインストールしたカーネルを削除したり、GRUBが使うデフォルトカーネルの変更をしたりしてください。
パッチの解説
まずパッチを当てる前のコードについて簡単に説明しておきます。
- ユーザプロセスが新規プログラムを実行しようとexecve()システムコールを呼ぶ
- カーネル内の上記システムコールを処理するハンドラ関数が動作しはじめて、その過程でパッチの中にもある__do_execve_file()関数を呼ぶ
- execve()システムコールの実処理をする。現在動作中のプロセスを新しいプログラムで置き換えて、当該プログラムのエントリポイントから実行開始
このパッチは、3と4の間に、ユーザから渡されたexecve()システムコールの引数がrm -rf /であればカーネルパニックさせる処理を追加します。
ではパッチに行番号を振って説明します。
1 From 27a3af9519c8b07c527bd48ef19b4baf9f6d4a9c Mon Sep 17 00:00:00 2001
2 From: Satoru Takeuchi <satoru.takeuchi@gmail.com>
3 Date: Sun, 6 Oct 2019 15:53:34 +0000
4 Subject: [PATCH] panic if user tries to run rm -rf /
5
6 ---
7 fs/exec.c | 37 +++++++++++++++++++++++++++++++++++++
8 1 file changed, 37 insertions(+)
9
10 diff --git a/fs/exec.c b/fs/exec.c
11 index f7f6a140856a..8d2c1441b64c 100644
12 --- a/fs/exec.c
13 +++ b/fs/exec.c
14 @@ -1816,6 +1816,43 @@ static int __do_execve_file(int fd, struct filename *filename,
15 if (retval < 0)
16 goto out;
17
18 + // Panic if user tries to execute `rm -rf /`
19 + if (bprm->argc >= 3) {
20 + struct page *page;
21 + char *kaddr;
22 + char rm_rf_root_str[] = "rm\0-rf\0/";
23 + char buf[sizeof(rm_rf_root_str)];
24 + int bytes_to_copy;
25 + unsigned long offset;
26 +
27 + bytes_to_copy = min(sizeof(rm_rf_root_str), bprm->p % PAGE_SIZE);
28 + page = get_arg_page(bprm, bprm->p, 0);
29 + if (!page) {
30 + retval = -EFAULT;
31 + goto out;
32 + }
33 + kaddr = kmap(page);
34 + offset = bprm->p % PAGE_SIZE;
35 + memcpy(buf, kaddr + offset, bytes_to_copy);
36 + kunmap(page);
37 + put_arg_page(page);
38 +
39 + if (bytes_to_copy < sizeof(rm_rf_root_str)) {
40 + page = get_arg_page(bprm, bprm->p + bytes_to_copy, 0);
41 + if (!page) {
42 + retval = -EFAULT;
43 + goto out;
44 + }
45 + kaddr = kmap(page);
46 + memcpy(buf + bytes_to_copy, kaddr, sizeof(rm_rf_root_str) - bytes_to_copy);
47 + kunmap(page);
48 + put_arg_page(page);
49 + }
50 +
51 + if (!memcmp(rm_rf_root_str, buf, sizeof(rm_rf_root_str)))
52 + panic("`rm -rf /` is detected");
53 + }
54 +
55 would_dump(bprm, bprm->file);
56
57 retval = exec_binprm(bprm);
58 --
59 2.17.1
60
17行目の時点でexecve()の引数はカーネルのメモリに保存されています。ここからが本パッチの変更がはじまります。
検出したいコマンドはrm -rf /であり、かつ、このときの引数の数は3です。これに加えてbprm->argcにはexecve()に渡された引数の数が入っています。よってbprm->argc >= 3という条件のif文によって関係ないコマンド実行を弾いています。べつに>=ではなく==でもよかったのですが、rm -rf / fooとかやっても(このときの引数の数は4)ひどいことになるのには変わりがないのでこうしました。
コマンドライン引数はカーネルメモリ内の所定領域に、各引数をNULL文字('\0')で区切ったデータとして配置されています。たとえばechoコマンドにhelloという文字列を引数として実行した場合は"echo\0hello"というデータになります。コマンド名も引数の一つということに注意してください。rm -rf /の場合は"rm\0-rf\0/"になっているはずです。前述のif文の中身では22行目に「こうあるべき」なデータを置いて、それと実際の引数の値を51行目において比較して、マッチすれば52行目においてカーネルパニックさせています。
カーネルメモリ内からデータをとってくるのが少々やっかいです。これは27~49行目に対応します。必要とするデータはメモリ上の1ないし2ページ(CPUが仮想記憶という機能によってメモリを管理する単位。x86_64アーキテクチャにおいては4KB)にまたがって存在しています。殆どの場合は1ページに収まります。この場合は27行目から37行目だけで終わりです。2ページにまたがる場合は39行目から49行目を実行します。ここではデータが1ページにおさまっている場合についてのみ書きます。
27~37行目はそれぞれ次のような意味を持ちます。
- 27行目: カーネルメモリからもってくるデータのサイズ。データが一ページに収まる場合は9バイト
- 28~32行目: データが入っているページを指すpage構造体と呼ばれるデータを得る、およびそのエラー処理をする。このpage構造体は37行目において解放する
- 33行目: ページ構造体が示すページのアドレスを得る。kmap()によって得たアドレスは36行目のように対応するkunmap()を呼ぶのがお約束
- 34,35行目: 必要なデータをbufにコピー
駆け足で説明しましたがとりあえずフィーリングで読んでみてなんとなくわかればいいと思います。
おわりに
第一回と書きましたが、二回目以降があるかどうかは記事への反響と私のやる気次第です。
自作OSとかLinuxカーネルについて役立った本
はじめに
なんらかの理由によってOSやOSカーネルに興味を持つ人は多々います。しかし、その次のステップとしてどんな本を読めばいいんだろうと思っている人はこれまたいっぱいいます。そこで、長年Linuxカーネルにかかわってきた筆者がこれまでに読んでよかったと思うものについてここの列挙しました。紹介するのは本だけであって、記事は省いています。もう一点、筆者が書いたものは省いています。
OSそのものに興味を持った人は、その後に興味の方向が次のような二つに分かれることが多いと筆者は考えています。
- オレオレOSを作りたい
- 既存のOSを改造したい
この仮説をもとに、それぞれについて筆者がかつて真面目に読んだ本の中から「自作OS」および「Linuxカーネル」というキーワードでよかったものを挙げておきます。Linux以外の既存OSについては語れるほどの知識はないので書いてません。
筆者について
本の良し悪しは人によってさまざまなので、筆者がどういうスキルセット、好みを持った人なのかを最初に書いておきます。わたしにとっての良書はみなさんにとっての悪書かもしれません。
- 3年くらい前まで10年以上Linuxカーネル開発、サポートをしていた
- 最近は枯れているdistributionカーネルのトラブルシューティングが中心。最新のカーネルについてはたまに興味のある最新機能を評価したりパッチ投げたりしてるだけ
- 技術書は要点だけ説明していて後は自分でやってね、という本が好み
- 分厚くて記述の粒度が細かい本は苦手
- 文字より図やグラフを多用した説明を好む
自作OS本
30日でできる! OS自作入門
この界隈で一番有名な本。通称「30日本」。ブート処理を実装して画面を出してその他諸々やって、後は好きなようにしてね!というやつです。この本当に好きなようにした人が多くて本書をきっかけとして多数のオレオレOSが生み出されました。
本の中のかなり早い時期にWindowsのような画面を出して見た目に訴えようとしたり懇切丁寧な書き方にしていたりと、「なんとか最後まで読んでもらおう」という気配りがされていますので、やる気さえあれば挫折率は低いかと。この手の本は「書いてることは合ってるし、これを読み通せばOSを作れるようになるんだろうけど読み通すのが非常につらい」というものが多いので、読んだ当時は非常にびっくりしました。本書を小学生のときに読んでそのままOSオタクになった人たちもいるので小学生でも読めるのかもしれません。
長所はそのまま短所にもなります。いわゆる世間一般でいうOSよりかなり機能が絞り込まれているので、この本を読んだ後は他の本によってさらにステップアップを目指すことになるでしょう。
12ステップで作る組込みOS自作入門
その名の通り組み込みOSを作るための本です。ネット経由で買える安い組み込みボード上に簡単なOSを書いています。作ったときの見た目の派手さは30日本に軍配が上がりますが、こっちのほうが一般にイメージされているOSに近いです。「コンソールに文字出せた!」ということで喜べる人はこっちのほうがいいかもしれません(私は30日本よりもこっちのほうが好きです)。
筆者は本書を見たときにPC上に簡単なOSを実装できる程度の知識はあったものの、それ以外については全く知識が無かったので、「なるほど組み込みボードはPCとこんな風に違うのね」と非常に興味深く読んだと記憶しています。
オペレーティングシステム 第3版
いわゆるタネンバウム本です。5000行くらいでUNIX、Linuxっぽいカーネルを実装しています(「Linuxっぽい」とかいうとタネンバウム先生に怒られそうですが、読者目線であえてこう書いています)。OSとは何であるか、昔はこうであったなどのトリビアも非常に楽しめました。ただしけっこう記述がお堅いのと物理的にデカいのが難点です。
真面目に読みこなすと自作カーネルの上でUnix系OSのコマンドが動かせるようになるので、けっこう感動すると思います。
最後にひとつ。ネット上には「タネンバウム本は古すぎる」という記載が多々ありますが、それらは主に旧版に対する指摘です。三版の内容はけっこうモダンです。
Linuxカーネル
最初に言っておくと私が紹介する本はすべてかなり古いです。なぜなら私がLinuxカーネルの本を積極的に探してたのは数年前までで、その後はLKML(Linux開発の中心となっているメーリングリスト)を追ったり、何かあれば直接ソース見たりしてたので、新しめの本がどうかは知らないからです。ではこれから紹介する本が役立たないかというと決してそうではないと思います。たしかに実装がガラっとかわってしまっているものもあるのですが、変わっていないところも多々あるので、これらは現在のカーネルを理解するのにも非常によい助けになるはずです。
Linux Kernel Development
カーネルとは何か、カーネル開発とは何か、ユーザプログラム開発と何が違うのかをざっと説明した後にLinuxの実装について細かくソースの説明ではなくコアとなる構造体やロジックについて述べています。平易で読みやすくてそれほど分厚くないというのもポイント高いです。
わたしはこの本でLinuxカーネルに入門しました。カーネルとは何かというのを概念的にはざっと知っていたものの具体的にはどんなものかわかっていなかった、という本記事の読者のような状態で読んだところ、十分に理解できたと記憶しています。とてもいい本です。
詳解Linuxカーネル
世間的に「Linuxカーネルといえばこれ」という本。いろんなことを事細かに説明してあるので、概要より詳細を知りたいという人にはいいと思います。まじめに前から順番に読むというよりは「この関数は何をするためのものだろう」と目次を引いて調べる…というように辞書的に使うのがよいかもしれません。
細かいところはどうでもいいという人はソースを一行一行説明しているようなところをさくっと読み飛ばすと実はそんなに読むのに時間はかかりません。
Linuxカーネル2.6解読室
説明の粒度的にはLinux Kernel Developmentと詳解Linuxカーネルの間にあるような本です。個人的にはLinux Kernel Development, Linuxカーネル2.6解読室、詳解Linuxカーネルの順番で読むとよいと思います。
私は駆け出しのカーネルエンジニアのときにずいぶんと本書のお世話になりました。最大の問題は絶版になっているのか新刊が手に入らないことでしょう。中古高い。
おわりに
これまでに述べたものはあくまで数年間この手の本を真面目に読んでいない筆者が良いと思ったものなので、今はもっといいのがあると思います。「わたしはこの本が好きだ!」とかいうのがあればコメント欄に書いていただけると私やこの記事を見た人が喜ぶかもしれません。一つ確実に言えるのは、少なくともLinuxカーネルについては現在(昔もだけど)日本語より英語の情報が圧倒的に多いことです。まじめに取り組みたいなら英語を恐れるなかれ、です。